
- 金融
摘要
隐匿查询是指在查询方不暴露查询意图,同时又能保护数据方提供方数据库中其他数据的情况下获得得相关查询结果。实际使用的场景大多是跨广域网环境下基于关键字的查询。当前技术手段下的常用方法要么需要传输大量的数据,而单一业务的远距离传输专线带宽经常是10Mbps甚至更低,这会导致传输时间无法接受,要么只能做到基于序号序号(index)的查询,但实际使用时查询方很难知道自己要查询的信息位于数据方数据库的第几号,更普遍的情况是查询方使用关键字(如身份证号)直接进行查询。
为解决上述问题,华控清交设计了低带宽的基于关键字的查询方案,同时设计并量产了业界第一款半同态计算芯片以解决计算量大的问题,每块芯片板卡性能可媲美约1000个CPU核心。低带宽算法与业界首款半同态计算芯片,使得跨广域网的基于关键字的隐匿查询在实际中落地成为了现实。
前言
我们可以想象这样一种场景:金融机构或医疗单位掌握了大量有价值的数据,但出于隐私保护、数据安全和法律法规方面的考虑,这些机构无法将所有数据开放给其他用户;另一方面,作为查询方,其查询条件(如客户身份证号和手机号)有时候也具有较高的敏感性和商业价值。在这类场景下,查询方需要保护查询条件,数据方需要保护数据源(即除了被查的信息外不泄露任何其他信息),这便是隐匿查询的典型场景。
我们可以使用一个简单的例子加以说明:某信用机构拥有一系列居民的征信分数及征信记录等信息,某贷款机构想从征信机构查询一个借贷客户的信用分数,但贷款机构出于保护客户资源的考量,不愿泄露这位客户的身份证号,同时征信机构也不想泄露除了这位被查询的借贷客户信息之外的其他信息(如其他居民的征信分数)。在这类场景下隐匿查询可解决该问题。

隐匿查询是当前隐私保护计算应用场景中最常见的需求之一。典型的隐匿查询有两个参与方:查询方和数据方,这也意味着隐匿查询一般是一种跨广域网的点对点的计算,且计算直接发生在参与方(即端侧)。由于跨广域网通讯的带宽限制使得隐匿查询的性能对通讯量非常敏感,因此用端侧计算量的增加来换取通讯量的减少是一个合理的选择。我们使用软硬结合的方案解决了隐匿查询实用化的问题:使用半同态计算专用芯片对针对基于半同态加密且通讯量极少的隐匿查询软件方案进行加速。
隐匿查询根据实际使用情况可分为两类:基于序号的查询和基于关键字的查询。基于序号的查询是指查询方已经知道需要查询的数据位于数据源中的具体顺序位置(类似于使用数组的下标访问),这在实际使用中不常见;而基于关键字的查询则只需要查询方提供全局唯一的关键字(如身份证号、手机号、房产证编号等等)即可,这种情况更为常见与通用。因此,本文只讨论基于关键字的查询场景。
在密码学领域,隐匿查询有多种实现方法,包括不经意传输(OT)、全同态加密、半同态加密等。这些方法各有优劣,有的方法计算极快但需要消耗很多带宽,有的方法对算力要求很高但传输的数据量较少。在实际使用中,通过广域网进行远程查询时能够使用的带宽资源有限,即便是跨省专线,很多时候为查询类业务能够分配的带宽可能也只有10Mbps甚至更少,因此而像KKRT这种基于OT扩展的方法,虽然计算量较少,但即便是在量级为100万且单条数据长度为200字节的数据集上进行隐匿查询时传输的数据量就在700MB以上,这便导致了在10Mbps的带宽情况下仅花在数据传输上的时间就有将近10分钟;这在实用使用中是很难接受的。而基于同态的方法(包括半同态和全同态)可构造出使用极小带宽的软件方案,代价是消耗巨大的算力。
华控清交专注于打造业界最快、最强、高安全性的密文计算引擎,在密文计算算法、软件优化、硬件加速方面都做了大量业界领先的工作。对于使用范围极广的隐匿查询场景,我们设计了基于关键字的查询算法(已申请专利),该算法借助半同态加密的特性,能够在算法上做到高可扩展并且数据传输量极少,其代价是需要消耗大量算力。为了解决半同态计算耗时长的痛点,华控清交李艺博士带领的安全与芯片团队打造了业界第一块半同态加密计算芯片,王雪强博士负责了该芯片的架构实现与验证。该芯片极大地加速了Paillier等半同态加密计算,使得跨广域网的隐匿查询可以极快地完成。如此,在新算法+半同态加密芯片的双重加持下,隐匿查询可实现计算时间与通讯量的双重最优化,真正地实现在广域网环境中较大数据量的隐匿查询实用化。
本文将简要介绍我们的算法构造,以及业界第一块半同态加密芯片对隐匿查询的加速作用。
场景及算法
我们以金融场景为例展示我们设计的针对低带宽消耗的基于关键字的隐匿查询算法。
场景一:使用关键字在单数据源上查询
我们假设某金融机构拥有用户姓名、联系方式、家庭住址、借贷历史等信息,这些信息一般有几百字节或更多。我们解决这个问题的大致思路如下:
步骤一:将数据源分组构造多项式:假定数据方总共有N条数据,将其分为n1组,每组约有n2条数据(即N=n1×n2),每条数据是一个键值对(k, x),其中k是关键字,x是对应的数据,然后使用每组数据构造多项式,一般情况下我们可以取n=n1=n2,如此便有n2=N;
步骤二:计算密文多项式:查询方将其密文的关键字k加密后得到若干密文[k],[k2], [k3],... ,并将其发送给数据方。数据方可根据加密算法的同态性质计算得到每个多项式的值的密文,并使用特定的方法混淆并打乱,然后返还给查询方;
步骤三:解密得到查询结果:查询方解密得到的信息,即可得到是否查询成功以及查询成功后的查询结果。

我们设计的以上方法有如下特点:
- 通讯复杂度为O(√N),极大降低了通讯复杂度,而且实际上我们只要求分组数与每组元素个数的乘积等于元素总数,也就意味着实际上可以用更多的计算换取更少的通讯;
- 计算复杂度为O(N),但可完全并行进行,且计算占比较高,因此硬件加速效果明显;
- 多项式的生成在数据方拥有查询方公钥的情况下完全可以离线完成,也就是说之后的查询无需重复构造这些多项式;
- 只要求加密方法满足密文上的加法同态以及密文与明文的乘法同态,如此一来很多经典的同态算法都可满足此性质,如Paillier、ElGamal、BGV、FV等,不同加密方法所需的计算与通讯特性不同,可根据实际需要灵活选择。
需要注意的是,通过构造多项式做简单的关键字查询的方法古已有之[1],通过多项式做隐匿成员检测(private membership test, PMT)或隐匿求交(private set intersection, PSI)也是常见方法[2],我们结合了折叠查询的方法将二者融合起来,实现了在大数据量上进行基于关键字的查询并能大幅节省通讯量。此方法的核心思路是用计算量的增加换取通讯量的降低,确保了即便在1Mbps带宽下依然可以较快地完成通讯过程;我们进而使用华控清交研发的业界首款半同态计算芯片来解决计算量大的问题。
场景二:多数据源查询结果的聚合与比较
我们此讨论一个更有意思的场景——贷款反欺诈。许多银行或借贷机构需要评估贷款人的放贷风险,比如通过查询贷款人在不同银行的开卡数量是否大于一个阈值,或者在不同的借贷机构借贷总额是否大于预设阈值。这类场景可抽象成如下问题:查询方需要根据关键字查询多个数据源,并判断在多个数据源中得到对应的数值的总和是否大于某阈值。在这种场景中,查询方应该只能得到最终的比较结果,既无法得到该关键字在每个数据源查到的具体数值,也无法得到查到的数值的总和。下图形象地展示了该场景:查询方给各数据源发送加密的关键字k,各数据源使用密文计算的方法得到被查数据的密文并使用特定的协议将密文聚合,最终查询方得到的结果是聚合后的密文是否大于某阈值,而各数据源无法得到查询关键字k和阈值t。
我们实现这个方法的思路与场景一是类似的,最大的不同在于,每个数据源做完密文查询后并不立即返回,而是使用特定的协议进行聚合,聚合后与阈值t在密文上计算差值并使用随机数扰乱,如此便能确保查询方只得到最终的比较结果。
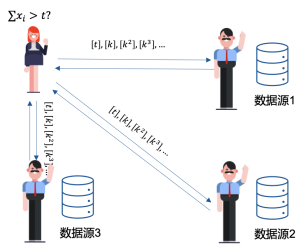
此方法有如下特点:
- 通讯复杂度同样为O(√N),适用于低带宽场景;
- 计算复杂度依然为O(N),同样可以由硬件加速极大地提升效率;
- 只要求加密方法满足密文上的加法同态以及密文与明文的乘法同态,避免了直接在密文上进行比较操作(直接在密文上计算比较电路要求加密方案支持全同态(FHE)或部分同态(Somewhat HE),且比较电路要求选择的参数支持好几层的操作,这会导致整体计算效率很低),因此支持半同态操作的加密方案如Paillier、Elgama、BGV、FV皆可使用。但需要注意的是,我们的方法要求最后一步解密随机分布的数据,因此椭圆曲线类的算法不适用。
通过以上场景及我们构造的方法,我们可以看到,使用纯粹的加法同态加密方案即可进行基于关键字的查询及后续的聚合比较操作,并且适用于低带宽的环境,剩下的就是要解决计算量的问题。这将由华控清交最新推出的大杀器——业界首款半同态计算芯片来解决。
业界首款半同态计算芯片
华控清交自2021年便开始半同态计算芯片的设计和流片,并于2022年三季度实现了量产。同时我们还为这款芯片专门设计了一款配套的板卡,其名为TsingJ Homomorphic Processing Card X1,尺寸为全高全长,且带主动散热,通过PCIe与上位机通讯,这意味着能插GPU的机器都可以使用我们的这款板卡。我们的芯片及板卡的如下特性确保了它在行业中的领先地位:
- 每块板卡可达到极高的吞吐量——计算模幂的性能可媲美约1000个CPU核;
- 单块板卡满负荷运载时的功率仅为约120W,能效比极高;
- 我们开发相应的驱动程序,可以在应用层无感知的情况下支持一卡多芯片、一机多卡、多机并行,提供极佳的数据并行能力,同时能在最小的空间中布置最多的算力。
通过下面的测试数据我们可以看到,我们的芯片板卡大战AMD旗舰处理器EPYC 7742也毫不费力。总之,有了华控清交的半同态计算芯片,处理隐匿查询既省时又省电,还能解放CPU,岂不美哉!
关于这款芯片,我们会另行召开序列专题推介会,并将在明年年初批量出货,下面先放上一张实际板卡照片,作为非正式亮相。

其他方案及性能对比
我们既有了省流算法,又有专用芯片加持,那咱的隐匿查询组合是不是就所向披靡了呢?不要着急,咱们用数据说话。我们首先明确一些测试的前置条件,然后列出实测的性能数据。
测试场景
我们将分别对上述两种场景做测试:
- 场景一:两方隐匿查询,数据方有100万条数据,每条数据大小为240字节,关键字长度为8字节(足以编码身份证号);
- 场景二:一个查询方和两个数据方,每个数据方同样有100万条数据,关键字长度为8字节,每条数据是一个4字节的整数(如借款额度)。
测试环境
针对两种场景,每个参与方独立使用一块AMD EPYC 7742(64核心128线程),所有的软件算法均在该款CPU上运行,而在测试芯片性能时每方独立使用两张芯片加速卡,这样我们就能看到一块AMD EPYC 7742和两张芯片加速卡的性能对比情况。之所以这么对比,是因为一颗AMD EYPC 7742的TDP为225W[3],而两块芯片板卡满负荷运载的功率则是240W左右,再加上CPU的实际工作功率会略大于TDP,所以这么对比是比较客观的。
网络方面,我们考虑到隐匿查询一般都是跨域的,即很少会在一个局域网内进行隐匿查询。而跨域网络,无论是专线还是公网,在实际使用中能稳定提供给一项业务的带宽都不会很高,因此我们这里设置了100Mbps、10Mbps、1Mbps三种情况。
对比算法
我们首先设立一个基准方案:将前文所述算法中的半同态加密方法用Paillier实现,密文长度为4096比特,以此为基准方案。
然后我们在此只对比有竞争力的算法,即计算或通讯至少有一方面能比基准方案更优的方法,这样对比才有价值;而对于那些计算和通讯理论性能下限皆不如基准方案的情况,我们在此就不予考虑了。因此前述方案中同态加密使用BGV、FV等实现的方案就不予考虑了,因为它们的计算量和通讯量相较于基准方案均处于劣势。同时,最近也有不少基于部分同态加密(somewhat homomorphic encryption)的方案[4,7],所需带宽极少且性能较高,但这些算法目前只在基于序号的隐匿查询上取得了较好的效果(这个表述是否会存在争议?),因此这类方案也不在考虑范围之内。
对于场景一,最终我们选择了两类算法做对比:
- KKRT[5]:参数选择参考原论文,此方案算力消耗极少,计算效率高,可以说是目前学术领域两方查询的state-of-the-art,奈何中间依赖OT Extension的变种方法做OPRF,导致通讯量极高,不适合带宽有限的广域网场景;
- ECC-ElGamal[6]:原生的ElGamal和Paillier一样是基于模幂的,相对Paillier而言并无优势,但近来有些工作将ElGamal中的模幂替换为椭圆曲线(elliptic curve, ECC),计算效率相较于CPU版本的Paillier有所提升,同时通讯量虽然比基准方案稍大但也远小于KKRT,当然由于ECC本身只能用于椭圆曲线上点的加法,而无法直接用于数值加法,因此需要一些工作将数值编码成椭圆曲线上的点,这些本身也会耗费一些计算量,我们选择的曲线是NID_X9_62_prime256v1。
而对于场景二,由于KKRT中间结果无法进行同态聚合,因此也就与我们的测试无缘了,剩下的只有ECC-ElGamal。但ECC有一个硬伤是其解密较大整数(如64bit或更多)时其性能接近于不可用,而我们针对场景二的最后一步计算中需要解密一个在明文域随机分布的数字,这便导致了ECC-ElGamal虽然能顺利完成前面的计算,但无法解密得到最终结果。
测试数据
场景一:1个关键字查100万条数据,关键字长度为8字节,每条数据长度为240字节
|
算法 |
总通讯量 (MB) |
端到端执行时间(秒) |
||
|
100Mbps |
10Mbps |
1Mbps |
||
|
KKRT |
709.5 |
59.5 |
570.2 |
5678.8 |
|
ECC-ElGamal |
3.83 |
141 |
144.1 |
171.2 |
|
Paillier(软件) |
0.976 |
266.8 |
267.8 |
275.3 |
|
Paillier(硬件) |
0.976 |
14.6 |
15.1 |
22.2 |
场景二:1个关键字查2个数据源,每个数据源各有100万条数据,关键字长度为8字节,每条数据为4字节整数
|
算法 |
总通讯量 (MB) |
端到端执行时间(秒) |
||
|
100Mbps |
10Mbps |
1Mbps |
||
|
ECC-ElGamal |
1.71 |
- |
- |
- |
|
Paillier(软件) |
2.91 |
267.5 |
270.2 |
290.2 |
|
Paillier(硬件) |
2.91 |
14.9 |
16.8 |
37.5 |
从上面两张表格中我们可以看出,对于场景一,KKRT在低带宽的情况下已经完全不可用了,而我们硬件加速的方案则一直保持在实用水准。而在场景二中,我们的硬件加速方案依然提升巨大。总的来说,华控清交的软硬件结合隐匿查询方案在计算性能、带宽、能效比这些指标上均遥遥领先。
结语
隐匿查询是数据价值流通的重要场景,虽然学术界已积累了相当数量的研究成果,但如何在实践中,尤其是带宽受限的情况下,让隐匿查询能够实用化,是一个值得探索的问题。我们的解决方案包括了软件和硬件的多个创新,具有省流算法+专有芯片的双重加持,能够多快好省地解决隐匿查询问题:
- 多:应用场景广、能处理的数据量大;
- 快:省流算法有利于快速完成传输,专用芯片则极大提升了计算效率;
- 好:多+快+省=好;
- 省:省流量、省时间、省功耗、省空间。
本文是我们半同态计算芯片应用系列文章的第一篇,未来我们还将展现更多关于该芯片的应用成果,敬请期待!
参考文献
[1] Boneh, Dan, et al. "Private database queries using somewhat homomorphic encryption." International Conference on Applied Cryptography and Network Security. Springer, Berlin, Heidelberg, 2013.
[2] Chen, Hao, et al. "Labeled PSI from fully homomorphic encryption with malicious security." Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. 2018.
[3] https://www.amd.com/en/products/cpu/amd-epyc-7742
[4] Ali, Asra, et al. "Communication–Computation Trade-offs in PIR." 30th USENIX Security Symposium (USENIX Security 21). 2021.
[5] Kolesnikov, Vladimir, et al. "Efficient batched oblivious PRF with applications to private set intersection." Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. 2016.
[6] Potey, Manish M., Chandrashekhar A. Dhote, and Deepak H. Sharma. "Efficient homomorphic encryption using ECC-ElGamal scheme for cloud data." 3rd international conference on electrical, electronics, engineering trends, communication, optimization and sciences (EEECOS 2016). IET, 2016.
[7] Angel, Sebastian, et al. "PIR with compressed queries and amortized query processing." 2018 IEEE symposium on security and privacy (SP). IEEE, 2018.
![]()