
- 数据智能
- 复杂网络
- 反欺诈
近年来,随着科学技术的飞速发展,人类的生产和生活日益离不开各种各样的网络,我们已经步入了网络化时代。当我们拿起手机给家人、朋友或者同事拨打电话时,就在不知不觉中参与到了社交网络形成的过程中;当我们登上高铁或者飞机时,就可以享受交通网络给我们带来的方便;即使当我们躺在床上什么也不干时,大脑中的神经元们也会形成巨大的复杂网络相互传递信号,帮助我们思考或者行动。网络化时代让人与人之间的关系更加紧密,也给人类的生活带来的极大的便捷。
今天小Z就邀请ZRobot计量分析师Joey(研究方向:复杂网络)从以下几个方面跟大家分享复杂网络以及复杂网络的应用:
• 复杂网络的研究简史
• 复杂网络的统计特征
• 常见的复杂网络模型
• 网络挖掘——链路预测
• 网络挖掘——社团结构
• 利用复杂网络进行信贷反欺诈
复杂网络的研究简史
追溯复杂网络发展的足迹,其首先是得益于图论和拓扑学等应用数学的发展。因为从某种程度上来说,复杂网络就是将图论科学与物理领域中的非线性动力学、统计物理学、系统科学、计算机科学、社会心理学、传播学等学科结合起来形成的一个全新学科。对于一张复杂网络,如果不考虑其动力学等特征,将每个网络节点视为一个点,节点之间的连接关系视为连边,那么复杂网络其实就是一张图。
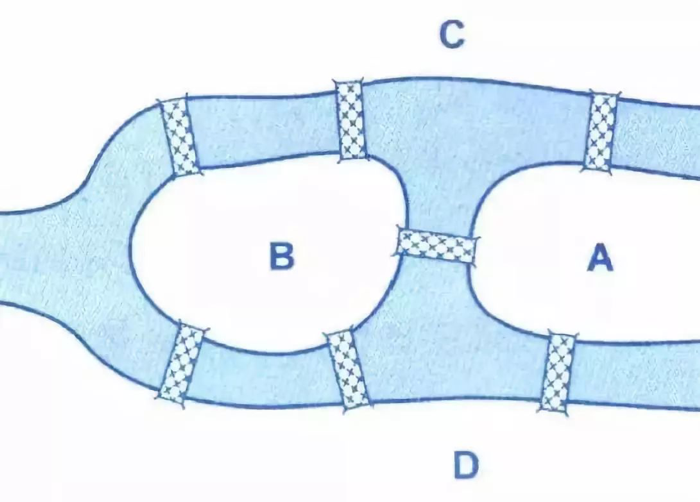
图论起源于著名的哥尼斯堡七桥问题。这里需要一张图。在哥尼斯堡的一个公园里,有七座桥将普雷格尔河中两个岛及岛与河岸连接起来。问是否可能从这四块陆地中任一块出发,恰好通过每座桥一次,再回到起点呢?欧拉于1736年研究并解决了此问题,他把问题归结为“一笔画”问题,证明上述走法是不可能的。
自欧拉1736年解决七桥问题之后,在相当长一段时间内图论其实并没有实质性研究进展,直至20世纪60年代左右,两位伟大的匈牙利数学家Erds和Rényi建立了随机图理论(Random Graph Theory),在数学上开创了随机图理论的系统性研究。在随后的 40多年里,随机图理论也一直是研究复杂网络的基本理论。
然而后来人们发现,在对一些现实网络的实际数据进行计算后,所得到的许多结果都与随机图理论是相背离的,因此迫切需要新的网络模型来更合理地描述这些实际网络所显示的特性。直到后来小世界性质与无标度性质的发现,复杂网络才得到了前所未有的发展,大批学者加入到复杂网络的研究行列中,在实证研究、演化模型、网络上的动力学等方面作了大量的研究。
复杂网络的统计特征
以上部分给大家简单介绍了复杂网络发展历史,下面我们从复杂网络的统计特征入手,让大家对复杂网络有一个更清晰、直观的了解。
网络的表示方法
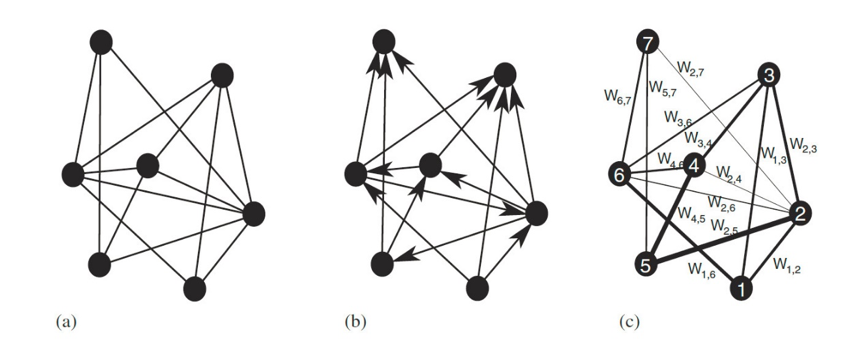
一个具体的复杂网络可抽象为一个由点集和边集组成的图。边集中每条边都有点集中的一对点与之相对应。
• 如果任意点对(i,j)与(j,i)对应同一条边,则该网络称为无向网络(Undirected Network),否则称为有向网络(Directed Network)。
• 如果给每条边都赋予相应的权值,那么该网络就称为加权网络(Weighted network),否则称为无权网络(Unweighted network)。当然,无权网络也可看作是每条边的权值都为1的等权网络。
此外,一个网络中还可能包含多种不同类型的节点。下面重点介绍的是无向无权网络,并且假设没有重边和自环(任意两个节点之间至多只有一条边,且没有以同一个节点为起点和终点的边)。在图论中,没有重边和自环的图称为简单图(Simple Graph)。
度及度分布
度(Degree)是单节点属性中非常简单而又重要的概念。节点的度就是该节点连接的其他节点的数目。度分布P(k)指一个随机选定节点的度恰好为k的概率。
平均路径长度
网络中两点之间的距离定义为连接两点的最短路径上所包含的边数。网络的平均路径长度指网络中所有节点对儿的平均距离。它反映了网络中节点之间的分离程度和网络的全局特性。有研究发现,虽然许多实际的复杂网络的节点数目巨大,但是网络的平均路径却小得惊人。
聚集系数
在你的朋友关系网络中,你的两个朋友很可能彼此也是朋友,这种属性称为网络的聚集特性,我们用聚集系数来定量地衡量这种特性。
节点的聚集系数是指与该节点相邻的所有节点之间连边的数目占这些相邻节点之间最大可能连边数目的比例。网络的聚集系数则是指网络中所有节点聚集系数的平均值,它表明网络中节点的聚集情况即网络的聚集性,也就是说同一个节点的两个相邻节点仍然是相邻节点的概率有多大,它反映了网络的局部特性。
介数
介数包括节点介数和边介数。节点介数指网络中所有最短路径中经过该节点的数量比例,边介数则指网络中所有最短路径中经过该边的数量比例。介数反映了相应的节点或者边在整个网络中的作用和影响力,具有很强的现实意义。例如,在交通网络中,介数较高的道路拥挤的概率很大;在电力网络中,介数较高的输电线路和节点容易发生危险。
常见的复杂网络模型
规则网络模型
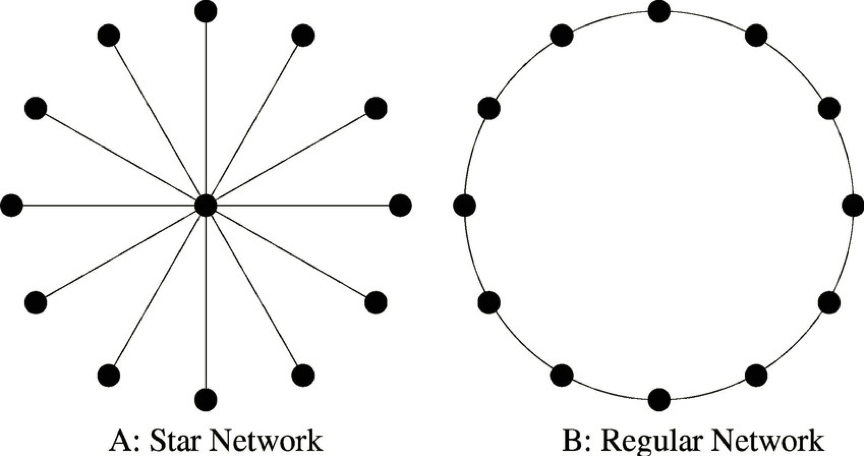
规则网络是最简单的网络模型。在这种类型的网络中,任意两个节点之间的连接遵循既定的规则,通常每个节点的近邻数目都相同。常见的具有规则拓扑结构的网络包括全局耦合网络(也称为完全图)、最近邻耦合网络和星型耦合网络。
ER随机网络模型
在抽象实际问题为网络问题过程中,如何在众多节点之间形成连边曾经困扰了许多科学家。在随机网络模型理论中,科学家们将该问题做了简化:节点之间是否产生连边是完全随机的,这一点与规则网络模型完全不同。
WS小世界网络模型
小世界网络模型是由瓦茨和斯特罗加茨在1998年《自然》上发表的《小世界网络的集体动力学》一文中提出的。他们发现,规则网络的群聚性较高,但网络之平均距离也大;而随机网络的平均距离较短,其群聚性也低。真实世界的网络既非完全规则,也非完全随机,而是介于这两者之间,于是有学者引入了小世界网络模型。
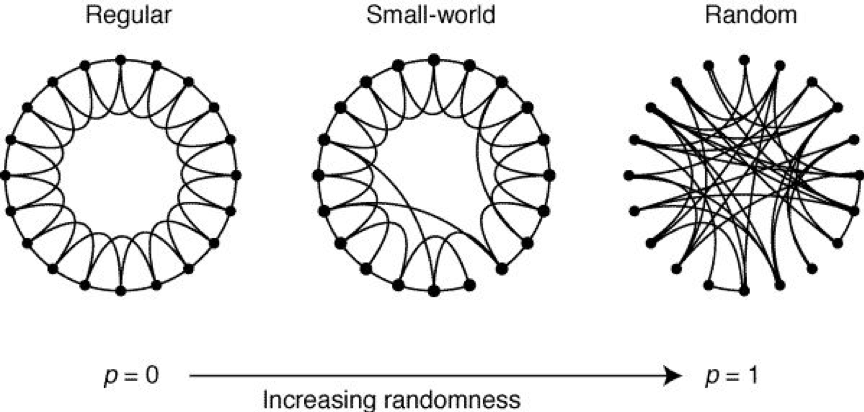
小世界网络的特征就是平均路径较短,而聚类系数较大。六度分隔(Six Degrees of Separation)讲的就是这个道理,可通俗地阐述为:你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过六个人你就能够认识任何一个陌生人。那么问题来了,为什么是六个人呢?六这个数字是怎么得来的呢?
1967年,美国哈佛大学社会心理学教授斯坦利·米尔格兰姆对这个问题做了一个著名的实验,他从内布拉斯加州和堪萨斯州招募到一批志愿者,随机选择出其中的三百多名,请他们邮寄一个信函。信函的最终目标是米尔格兰姆指定的一名住在波士顿的股票经纪人。由于几乎可以肯定信函不会直接寄到目标,米尔格兰姆就让志愿者把信函发送给他们认为最有可能与目标建立联系的亲友,并要求每一个转寄信函的人都回发一个信件给米尔格兰姆本人。出人意料的是,有六十多封信最终到达了目标股票经济人手中,并且这些信函经过的中间人的数目平均只有6个。也就是说,陌生人之间建立联系的最远距离是6个人。1967年5月,米尔格兰姆在《今日心理学》杂志上发表了实验结果,并提出了著名的“六度分隔”假说。当然随着互联网的发展,如今可能不用六个人就可以认识任何一个陌生人。
BA无标度网络
这里需要一张图无标度网络是在网络中的大部分节点(小度节点)只和很少节点连接,而有极少的节点与(大度节点)非常多的节点连接。其中,大度节点也被称为网络中的枢纽,它们的存在使得网络对意外故障有强大的承受能力,与此同时,面临协同攻击时则显得异常脆弱。这种现象抽象为数学概念来讲就是无标度网络的节点度分布服从幂律分布。现实生活中,有很多网络都是无标度网络。
无标度网络是说,现实网络是不断扩大不断增长的,例如互联网中新网页的诞生,人际网络中新朋友的加入,新的论文的发表,航空网络中新机场的建造等等。而新的节点在加入网络时会倾向于与有更多连接的节点相连,例如新网页一般会有到知名的网络站点的连接,新加入社群的人会想与社群中的知名人士结识,新的论文倾向于引用已被广泛引用的著名文献,新机场会优先考虑建立与大机场之间的航线等等。这种“富者更富”的效应就是一些现实世界网络增长模式的特征。
网络挖掘——链路预测
链路预测是指如何通过已知的网络结构等信息,预测网络中尚未产生连边的两个节点之间产生连接的可能性。预测那些已经存在但尚未被发现的连接实际上是一种数据挖掘的过程,而对于未来可能产生的连边的预测则与网络的演化相关。
链路预测具有重大的实际应用价值。例如在人人网等社交产品中,可以通过链路预测算法为用户推荐其尚未添加好友,但是可能认识的朋友,并将此结果作为“朋友推荐”发送给用户,有助于提高用户的忠诚度;另外,链路预测也可以应用在电商网站中。如果将电商网站中的商品看成一类节点,用户看成另一类节点,如果用户A购买了商品b,A与b之间则形成一条连边,这种边只在不同类型的节点间存在的网络成为二分网络,而在二分网络中的链路预测问题其实也是推荐系统的一种,推荐系统的重要性不必多说。
这里需要一张图那么问题来了,如何在社交产品中预测用户可能认识的朋友呢?一个比较简单的思路就是,如果两个人之间的共同好友越多,他们是好友的概率越高,这个就是著名的Common Neighbor算法。我们设想以下场景,假如某中学学生A与B、C在人人网都没有互加好友,其中A与B是同学企鹅都在3年1班,C同学在3年51班,每个班级内基本都有互加好友,那么在人人网中,A与B认识的概率更大呢还是A与C认识的概率更大呢?显然是B。于是站在人人网的角度,为A同学推荐B同学是一个比较明智的策略。

但是,在某种程度上来说,Common Neighbor算法也有其局限性。试想在上述例子中,我们考虑一个极端场景,学生会主席D同学也注册了人人网账号,并且添加了除A同学外所有的三年级学生,那么对于A同学来说,A的所有好友都是D的好友,但是B同学对于A来说可能更加熟悉,那么人人网为A推荐B同学还是D同学呢?
也就是说,如果一个网络中存在某些超级节点,在使用Common Neighbor算法的过程中,就会面临推荐超级节点的问题。为了解决这个问题,科学家们基于Common Neighbor算法衍生了诸如Salton算法、Jaccard算法、Sorenson算法、大度节点有利算法(hub promoted index)、大度节点不利算法(hub depressed index)和LHN-Ⅰ算法等等,当然还有更多基于随机游走以及基于路径的预测算法,这些算法在这里就不一一介绍了,有兴趣的读者可以阅读相关文献来进一步学习。
网络挖掘——社团结构
战国策有云:“物以类聚,人以群分”,同一群鸟儿总是聚在一起飞翔,同一类野兽也总是聚在一起出没。随着对复杂网络研究的不断深入,人们发现在实际的复杂网络中,普遍存在着共同的性质:一组组内的节点之间有着较大的相似性,而与网络中其他部分节点有着较小的相似性。我们将这种结构称为社团结构。
社团结构最早由Girvan和Newman提出,后来逐渐被人们接受和应用。目前对于社团结构的研究已经持续了十年左右的时间,已成为复杂网络研究领域中的一个重要的研究热点和方向。科研人员通过深入研究社团结构能更加深刻地认识网络的动力学行为,可以说,社团结构是理解整个网络结构和功能的重要途径。
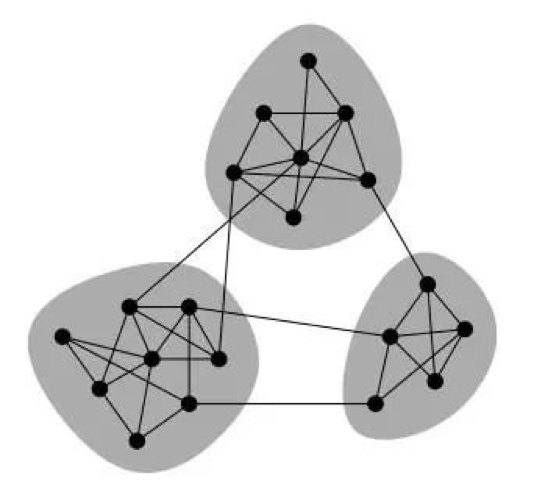
随着关注网络社团结构问题的科研工作者不断增加,众多划分网络社团结构的算法被设计出来。根据不同的标准,这些算法可以被分成不同的种类。例如:根据社团结构的形成过程,算法可以分为凝聚算法、分裂算法、搜索算法及其他算法4大类。从算法的物理背景上考虑,又可以将其分为基于网络拓扑结构的算法,基于网络动力学的算法,基于Q函数优化的算法及其他算法。
那么网络社团结构分析有哪些应用呢?一个比较有趣的场景就是个性化推荐系统。讲道理的话,同类的人群更倾向于拥有更相似的行为,如在电子商务网站上更倾向于购买同类的物品,在同类的社团中更倾向参加同类的活动等等。那么,如果通过对网络社团的挖掘,识别出兴趣、偏好相似的用户,是不是就可以为该社团的成员推荐其他成员感兴趣的事物呢?
利用复杂网络进行信贷反欺诈
欺诈风险是消费金融业务中存在的主要风险之一,它是指信贷客户完全不具备还款意愿一类的风险,很多金融机构的坏账都是由欺诈产生。因此,需要构建有效的风险控制体系,贷前反欺诈环节是帮助金融机构过滤劣质用户,筛除欺诈人员的第一道风控环节。
传统的反欺诈风险方法主要是基于通过SDK采集的个人行为数据、利用爬虫等技术爬取的消费和通信数据以及来源于第三方机构的用户数据,使用逻辑回归、随机森林、神经网络等机器学习方法构建评分模型,定量评估新进客户的欺诈风险。在如今的大数据时代,通过对海量数据的整合,建立的反欺诈系统为金融机构的风控打开了一扇天窗。
但是,欺诈风险目前日益呈现产业链化的特征,围绕着欺诈的实施,形成了专业的技术开发产业,比如虚拟模拟资料,账单造假等;身份信用包装和虚假身份提供产业,比如到农村收一些大爷大妈的身份证等;业务漏洞发现和欺诈方法传授产业,而且从事这些产业的人都具有较高的智商,他们会各种试探金融机构的反欺诈规则,然后利用前两种产业提供的技术、资料实施欺诈。这种团伙欺诈有时不容易被侦测,使用人工智能算法识别可能产生漏网之鱼,通过复杂网络的挖掘方法可以有效弥补这一缺点。
首先,通过SDK可以实时采集用户的各项数据,比如手机设备号、数据网络、地理位置等信息。另外,通过抓取用户通信运营商的数据可以获取用户的通信记录等。有了这些数据,我们可以通过其中的关联关系建立巨大的复杂网络,比如有一些账号的手机设备手机号是相同的,或者使用同一个WIFI,或者同一个基站,或者手机号码之间有通信记录等等。建立网络之后,我们就可以对这张网络进行深度分析与挖掘。
挖掘方法包括但不限于以下几点:
• 网络中的孤立节点,这些节点与其他节点没有连接,往往是比较安全的节点;
• 网络中的超级节点,这些节点的度巨大,是网络中的“枢纽”,有较高的概率是欺诈团伙的一员;
• 节点的聚集系数,集聚系数较大的节点往往处于某个小社团内部,这种社团是欺诈团伙的概率很高;
• 挖掘网络中的社团结构,然后针对每个社团进一步分析社团内部的统计特征,分析该社团是欺诈团伙的可能性;
• 等等
通过上述方法对网络进行分析之后,我们可以得到一些有欺诈风险的社团,进而可以建立黑名单团伙。另外,由于金融机构每天都会有新用户源源不断地进入,还可以通过计算新用户与黑名单团伙的关联关系,实时计算新用户的欺诈倾向。
小结
综上,我们从复杂网络的研究简史出发,简单介绍了复杂网络的基本特征、几种基本的网络模型、网络挖掘方法以及在信贷反欺诈中的应用。反欺诈是金融行业永恒的主题,尤其是进入大数据、人工智能时代,欺诈风险逐渐成为信用风险之外的一个主要风险,为此需要深入应用复杂网络分析等智能化算法,将反欺诈手段进行持续升级和优化。
如果各位看官对复杂网络及网络挖掘方面感兴趣,下方的文献供大家参考,更多奥秘等你来探索。
参考文献
[1] Albert, R., &Barabási, A. L. (2002). Statistical mechanics of complex networks. Reviewsof Modern Physics, 74(1), 47.
[2] Dorogovtsev, S.N., & Mendes, J. F. (2002). Evolution of networks. Advances in Physics, 51(4),1079-1187.
[3] Newman, M. E. J.(2003). The structure and function of complex networks. SIAMReview, 45(2), 167-256.
[4] Boccaletti, S.,Latora, V., Moreno, Y., Chavez, M., & Hwang, D. U. (2006). Complexnetworks: Structure and dynamics. Physics Reports, 424(4), 175-308.
[5] Dorogovtsev, S.N., Goltsev, A. V., & Mendes, J. F. (2008). Critical phenomena in complexnetworks. Reviews of Modern Physics, 80(4), 1275.
[6] Strogatz, S. H.(2001). Exploring complex networks. Nature, 410(6825), 268.
[7] Wang, X. F., & Chen,G. (2003). Complex networks: small-world, scale-free and beyond. IEEECircuits and Systems Magazine, 3(1), 6-20.
[8] Alon, U. (2007). Network motifs:theory and experimental approaches. Nature Reviews Genetics, 8(6),450-461.
[9] Costa, L. D. F., Rodrigues, F. A.,Travieso, G., & Villas Boas, P. R. (2007). Characterization of complexnetworks: A survey of measurements. Advances in Physics, 56(1),167-242.
[10] West, B. J., Geneston,E. L., & Grigolini, P. (2008). Maximizing information exchange betweencomplex networks. Physics Reports, 468(1), 1-99.
[11] Estrada, E., Hatano,N., & Benzi, M. (2012). The physics of communicability in complexnetworks. Physics Reports, 514(3), 89-119. 12] Newman, M. E. J.(2012). Communities, modules and large-scale structure in networks. NaturePhysics, 8(1), 25.
[13] Liu, Y. Y., &Barabási, A. L. (2016). Control principles of complex systems. Reviews ofModern Physics, 88(3), 035006.
[14] 吕琳媛. 复杂网络链路预测[J]. 电子科技大学学报, 2010, 39(5):651-661.
内容来源:文章来自ZRobot计量分析师Joey(研究方向:复杂网络)的应用分享。爱分析经作者审阅授权发布。