
- 数据智能
- 隐私计算
- 数据隐私与安全

随着企业数据量增加,跨行业、跨领域的数据共享和应用成为企业刚需。隐私计算帮助企业在保障数据和隐私安全的前提下使用数据、挖掘数据的价值,并率先在金融行业落地,吸引了大量厂商入局。但隐私计算技术门槛高,客户对产品和服务的需求多元,场景落地难,隐私计算概念热炒的当下,如何辨析真正具有实力的厂商?隐私计算未来的发展趋势是怎样的?
数据时代催生安全共享需求,隐私计算正当时
2019年,Gartner在Hype Cycle中首次将隐私计算列为处于启动期的关键技术。2020年,Gartner又发布了企业机构在2021年需要深挖的九大重要战略科技趋势,隐私增强计算入选其中。Gartner认为,到2025年,全球将有一半的大型企业机构使用隐私增强计算在不受信任的环境和多方数据分析用例中处理数据。
随着互联网、物联网等技术的发展,企业面临海量数据的处理与分析任务。同时,全球数据保护法规愈发成熟,企业在使用数据过程中面临着隐私泄露和数据使用违规风险。而隐私计算不仅可以保护数据安全,同时可保护正在使用的数据,成为企业进行数据应用的重要支撑。
众多数据应用场景需要多方数据共享
2020年4 月,《中共中央国务院关于构建更加完善的要素市场化配置体制机制的意见》公布,数据作为一种新型生产要素,与土地、劳动力、资本、技术等传统要素并列为要素之一。2020年10月,“十四五”规划发布,其中明确提出:新时代的数据不再是传统意义上的数据,要明确数据作为核心生产要素的重要性。只有正确认识数据的生产价值与重要性,有计划地安排、使用好数据,才能为科技创新提供更多可能。相应地,与数据相应的法律监管等基础设施也会不断完善。
企业进入数据要素时代,数据流通、共享与协同成为数字经济时代企业的刚性需求。企业自身的数据是单一有限的,而越来越多的业务场景需要多方数据共享。因此,企业需要与同行业或产业链上下游企业进行合作,进行多方数据共享,以释放数据的应用价值。
在金融领域,银行的众多业务场景需要结合外部数据的联合建模,包括数字营销、风控与反欺诈、存客激活与信用分析等。保险公司在精准获客与保险定价环节,需要多维度数据支撑,包括消费者的资质信息、购买能力、身体状况等,以便为不同的消费人群提供定制化的保险产品与服务。
在医药领域,数据是进行精准医学、AI制药的核心要素。医疗机构中的病例数据是最重要的隐私数据,但单个医疗机构的数据样本不足以支撑大规模的模型训练,需要多方共享。
政务领域具有较完备的数据基础,但政务涉及能源、交通、规划、环保等多行业和多部门的数据共享与协同,需要打通并共享各部门数据,才能支撑各项应用。
隐私安全保护是多方数据共享的前提
数据要素的流通和共享已经成为数据价值释放的必然要求,但企业业务所需要的数据往往包含用户隐私数据或内部数据,出于自身利益和隐私泄露风险等考量,大部分高价值数据拥有方无法直接共享数据,数据价值无法体现。同时,数据的共享和安全保护技术与制度尚不成熟,全球频现隐私泄露事件。
在合规与监管层面,欧盟GDPR规定了违反数据隐私法规的严厉制裁和巨额罚款,是目前最全面、应用最广泛的隐私保护法规之一。
中国的法律对数据安全与合规的要求也明显趋严。2016年11月,中国发布《网络安全法》,要求互联网企业不得泄露或篡改收集得到的用户个人信息。2020年最新发布的《民法典》也已纳入个人信息保护的相关内容。人大、央行、工信部、公安部等各大监管都出台了⼀系列政策,对数据的安全利用提出了更加为严格的要求。
在全球数据监管趋严的局势下,数据获取困难制约需求方的业务发展,企业需要提供安全数据流通的解决方案;在部分行业,受监管推动,企业亟需获取更多的数据维度,构建更精准的AI算法模型指导业务发展。例如,由于疫情影响,国家加大了对于小微企业的扶持和放贷力度,金融机构为了在风险控制的范围内实现监管的放贷要求,需要获取更多数据从而对小微企业的还款能力和意愿进行更准确的判断。
如何兼顾数据的可用性和隐私安全保护,实现海量数据实现数据流动的同时保护数据隐私安全、防止敏感信息泄露,成为行业核心关注点。现有的数据隐私保护方案主要是针对静态数据的保护,大都聚焦于相对孤立的应用场景和技术点,针对给定的应用场景中存在的具体问题提出解决方案,但是无法对计算和分析中的数据进行保护。因此,企业需要新型解决方案,“可用不可见”的隐私计算政策监管和需求的驱动下迎迎来发展契机。
隐私计算能够解决在数据的动态使用和分享过程中的数据安全性问题,实现跨系统隐私数据可用不可见,数据不出门、价值可流动,多业务之间的信息可安全合规地进行共享。
一方面,隐私计算的技术成熟度逐步提升,已在金融领域率先落地,未来可预见更多的落地应用场景;另一方面,技术巨头与初创企业投入隐私计算的研发与应用领域中,标志着隐私计算技术处于快速增长、即将爆发的时间点。
根据IDC的最新预测,2020年中国大数据相关市场的总体收益将达到104.2亿美元,较2019年同比增长16.0%;其中,大数据相关软件和服务的收入占比将持续提升。
作为大数据应用的保障设施和必要投入项,可以预见大数据安全市场也将迎来快速增长。随着三大运营商打造大数据安全开放平台,地方政府需要安全开放共享政务数据,金融机构需要在风控、营销场景中进行大数据内外融合,以及央企与部委开放共享相关数据,大数据安全计算与数据服务迎来极佳机会点。
隐私计算作为数据安全软件服务的重要应用,目前仍处于起步阶段。未来,随着数据应用的价值增加,隐私计算即将迎来广阔的发展空间。一方面,隐私计算通过更为安全的方式使得现有的数据交易能以更合规的方式进行,进而取代部分现有的数据交易市场;另一方面,隐私计算使得原来因为安全性的问题无法互通的数据实现互联互通,同时释放非结构化数据的价值,带来巨大增量市场。
隐私计算的技术体系
保护数据安全与隐私的环境和机制不仅仅在立法上,更是在技术解决方案上。
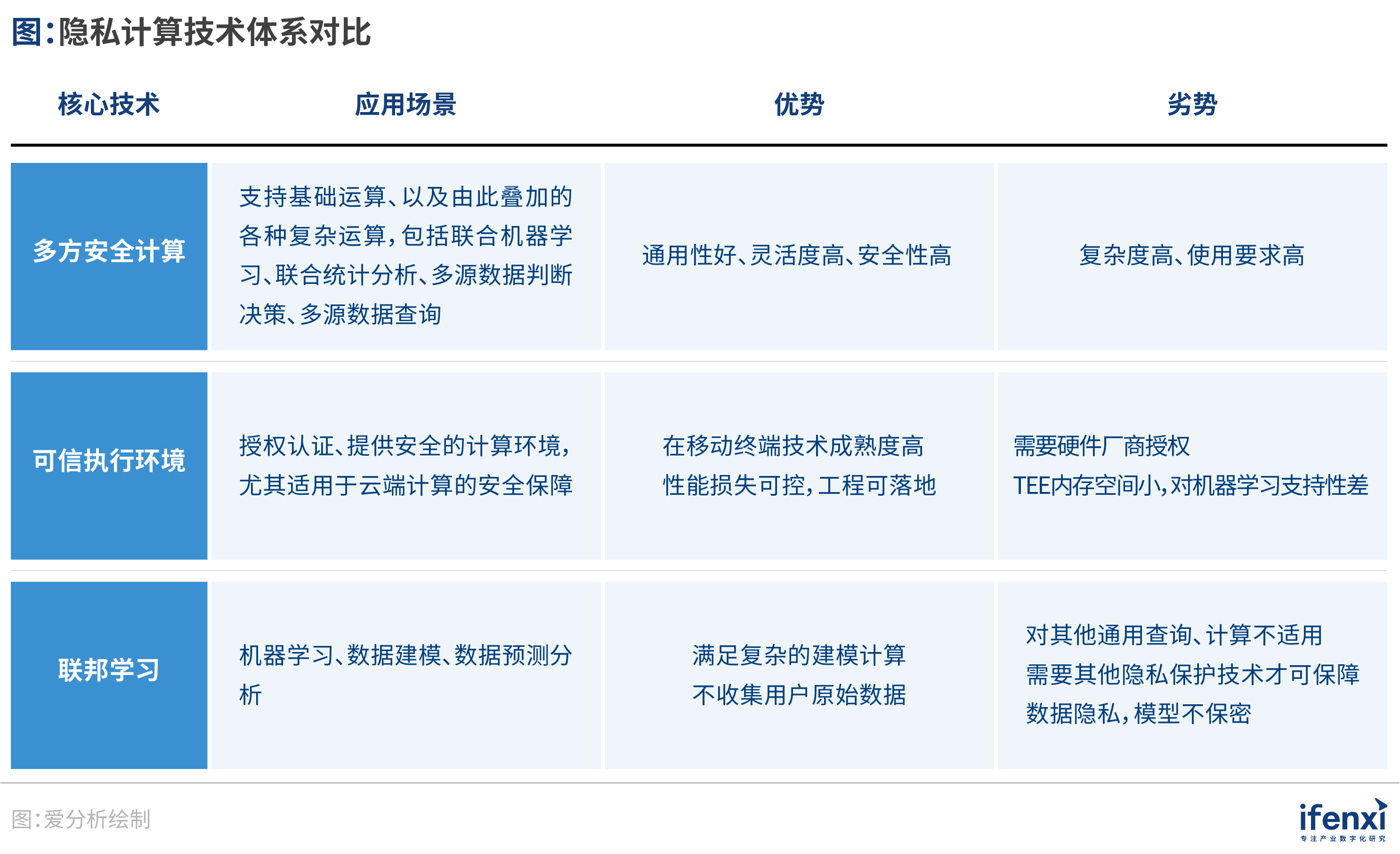
从技术层面来讲,企业对于隐私计算的核心需求场景主要有查询、统计分析、判断决策、机器学习等方面,其核心原则为保护数据隐私及数据输出准确,这需要复杂的技术体系作为支撑。目前,隐私计算的技术路线主要包括多方安全计算(MPC)、可信执行环境(TEE)和联邦学习。

1)多方安全计算
多方安全计算(Secure Multi-Party Computation,简称MPC)最初源于1982年姚期智院士提出的 “百万富翁”设想,两个百万富翁在街上相遇,在没有第三方的情况下,他们都想知道谁更富有,但又不愿意让对方知道自己拥有的真正财富。
MPC是指在无可信第三方情况下,通过多方共同参与,安全地完成某种协同计算。即在一个分布式环境中,多个参与者共同完成对某个函数的计算,该函数的输入信息分别由这些参与者提供,且每个参与者的输入信息是保密的,在计算结束后,各参与者获得正确的计算结果,但无法获知其他参与者的输入信息。这种方式主要基于密码学的一些隐私技术,相关概念还包括同态加密、不经意传输、混淆电路和秘密共享等。
2)可信执行环境
可信执行环境(TEE)基于硬件实现隐私计算,在计算机硬件平台上引入安全芯片架构,构建一个安全的硬件区域,各方数据统一汇聚到该区域内进行计算,通过其安全特性提高终端系统的安全性。TEE将信任机制交给硬件方(Intel的SGX、ARM的TrustZone、AMD的SEV等产品),其通用性高、开发难度低,使得在数据保护要求不是特别严苛的场景下发挥价值。
3)联邦学习
此外,面向机器学习的需求场景,衍生出了联邦学习、共享学习、知识联邦、联邦智能等一系列“联邦学习类”技术。这类技术以实现机器学习、数据建模、数据预测分析等具体场景为目标,通过对上述技术加以改进融合,并在算法层面进行调整优化而实现。
联邦机器学习是一个机器学习框架,基于多方数据进行联合建模,各自原始数据不对外输出,由中心方进行协调建模,能帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。
这三种方式在安全性、工程能力和落地场景等方面存在不同的特点。多方安全计算主要适用于统计分析、判断决策、查询;可信计算适用于数据保护要求较低的应用场景;联邦学习适用于机器学习。
国内隐私计算技术应用进入落地阶段,参与者众多
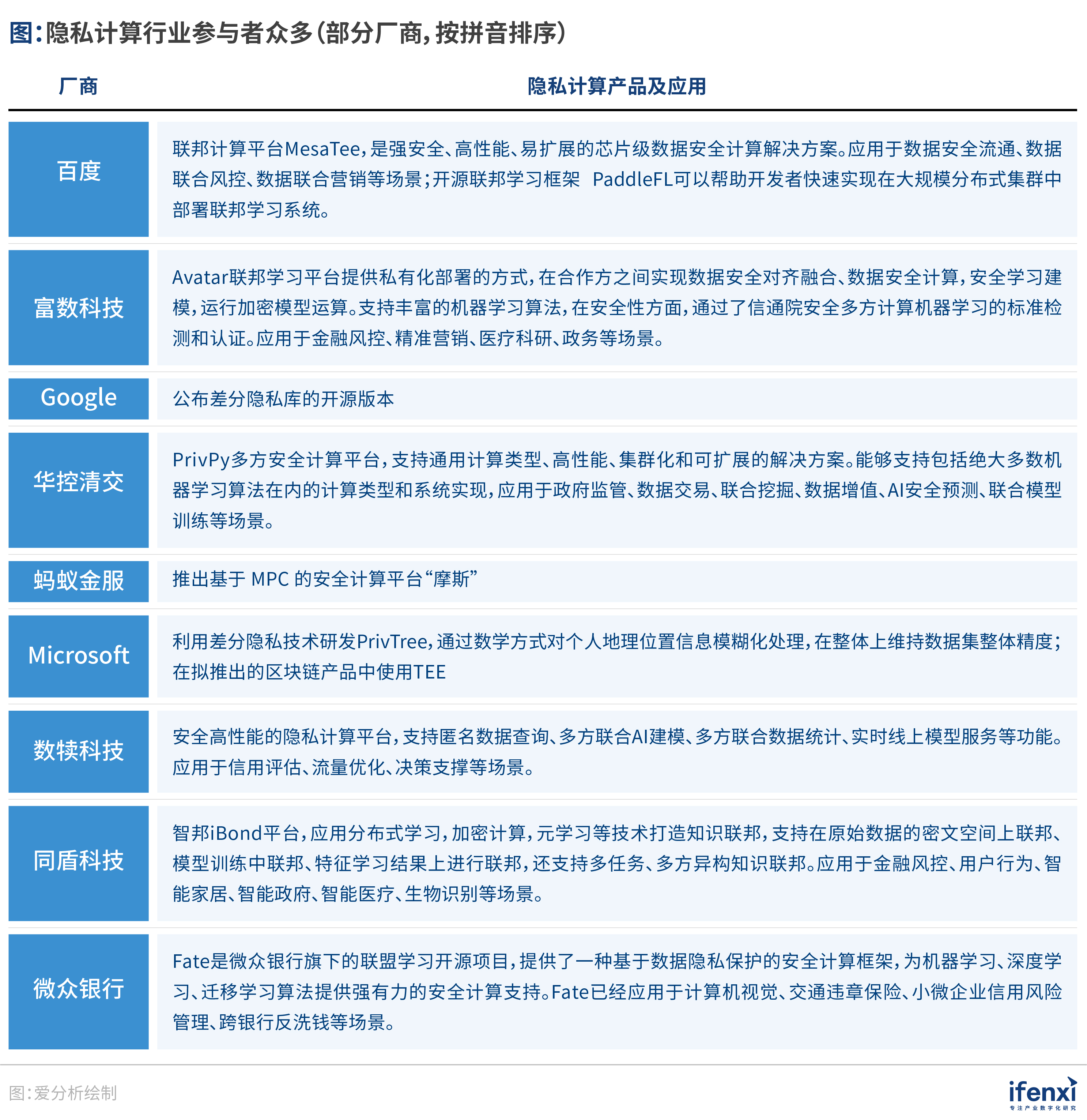
当前的隐私计算技术并不成熟,性能还无法支撑大规模商用;同时,市场成熟度低,市场教育仍处于起步阶段。但越来越多厂商开始进入隐私计算这一领域,包括互联网大厂以及具有先进技术与丰富落地经验的初创企业。
国外隐私计算技术产品创新活跃。2019年以来,国外科技巨头快速布局隐私计算产业,提升了行业对于隐私计算的认知,部分巨头开源了隐私计算库,降低开发门槛,建立行业影响力。例如,2019年4月微软新发布的两项专利申请表明,其正考虑在拟推出的区块链产品中使用TEE;2019年8⽉,Google推出新型多⽅隐私计算开源库;2019年10⽉Facebook将Secure Machine Learning框架CrypTen进行开源。
国内隐私计算技术产品发展迅速,产业化快速启动,已形成一定优势。一方面,随着算法协议的优化和硬件计算能力的增强,隐私计算的技术和产品成熟度迅速提升;另一方面,隐私计算技术的应用场景在不断扩展。
中国各互联网巨头企业也在隐私计算领域加快布局,蚂蚁金服、腾讯云、百度在 2019 年推出了各自的MPC产品,微众银行、京东等企业也在各自的领域形成一定优势。
此外,一批专注于隐私计算的技术巨头与初创企业也不断涌现。富数科技、华控清交等几家厂商掌握多方安全计算的核心技术,实现完全自主研发,且尚未开源,提供个性化MPC服务;微众的 Fate、百度的 PaddleFL、富数科技 Avatar和蚂蚁集团 Morse拥有联邦学习的自主知识产权,其中 Fate、PaddleFL 已开源,京东数科、平安科技等企业基于开源内核搭建了上层应用平台。
同时,也有诸多区块链企业、数据安全企业、金融风控企业等也纷纷投入隐私计算技术研发与应用中。
从行业落地情况来看,目前相对集中的落地场景主要在于金融、医疗、政务行业等。其中,金融行业是隐私计算的最佳切入点。首先,金融行业在隐私计算出现之前就存在较多的数据交易,由于监管趋严,业务中需要获取更多的数据完善相应的风控模型,对隐私计算的需求增强;其次,金融行业的客户付费能力强,有助于厂商增加收入;最后,金融行业作为企业数字化转型的先锋,数据基础设施完善,对数据安全的要求也最为严格,对于厂商来说是打磨产品的机会,也对拓展其他行业应用场景提供了很强的背书。
据了解,由富数科技、交通银行、中国移动、中国电信联合创新的“基于多方安全图计算的中小微企业融资服务”,根据用户资金往来关系图谱和用户通信图谱,识别高风险客户,不需要原始数据,也可以建立用户风险关系。该项服务开创了全球多方安全图计算的先例,入选中国人民银行上海总部发布的上海金融科技创新监管试点应用公示(2020年第一批)。现今,该服务将正式对外公开,成为国内金融领域首例对外公开运行的多方安全计算应用。
市场鱼龙混杂,如何评估隐私计算厂商能力?
大批厂商涌入隐私计算领域,隐私计算短时间内成为行业热炒的概念。这一方面有利于新技术的传播与教育,推动了市场发展;但另一方面,隐私计算从单一技术到场景落地面临诸多挑战,落地效果取决于厂商的多方面能力,包括产品、技术、实施与服务、生态建设等。而在市场发展初期,行业标准尚未完全建立,大批技术水平参差不齐的厂商进入,市场鱼龙混杂。
隐私计算未来的商业模式趋向平台化发展,但能够交付的隐私计算产品是一个巨大的、复杂的、困难的软件工程。因此,只有真正自主掌握隐私计算核心技术、具有完善的产品能力、能够流畅交付解决方案的厂商,才能成为客户信任的隐私计算平台。
爱分析认为,在当下的市场中,隐私计算厂商需要具备的关键能力包括底层技术能力、场景化应用能力、数据生态三方面。
技术先行,研发能力驱动持续创新
隐私计算的技术门槛较高,需要厂商具备较强的创新性研发能力。由于隐私计算技术大多是基于密码学,而密码学属于计算机理论,结合人工智能等技术,对研发人员长期的专业知识积累要求极高。因此,厂商的底层技术研发能力是其竞争力的核心标准,反映了企业的技术研发能力和创新能力,可从以下几方面进行判断。
第一,技术自研能力。“十四五”规划提出“坚持创新在我国现代化建设全局中的核心地位,把科技自立自强作为国家发展的战略支撑”,实现核心技术自主可控将成为未来核心主线,因此具有自研能力是科技厂商的核心竞争力之一。目前隐私计算厂商的自研情况可分为三类:完全自研、部分使用开源与完全依赖开源技术的厂商。尽管基于开源技术也可以提供很多应用场景的解决方案,但隐私计算的技术体系与落地应用复杂,企业自研底层架构能够提供更加灵活的解决方案,局限性小,能真正推动行业核心技术实现自主可控。
第二,技术深度与广度。深度指厂商能够实现的技术功能与优势,例如,厂商是否可以控制其建模误,厂商不仅需要给出python库的建模结果和联邦学习的建模结果误差系数,还需要给出整个联邦学习或者MPC的过程每个环节是准确计算、还是存在误差的计算,以判断这种误差是否会影响现有的模型稳定性。广度指对隐私计算技术体系的覆盖度。隐私计算不同的应用场景适用于不同的技术体系。对于核心技术体系覆盖越广、钻研越深的企业,越能覆盖企业的应用场景,解决客户不同的问题。
第三,自身科研力量。隐私计算涉及多种技术,包括密码学、机器学习算法等复杂内容,企业具有多元的行业科学家,是其技术研发能力和创新能力的重要支撑。
第四,行业测评认证与标准制定。为了普及隐私计算,需要尽快制定隐私计算技术标准化。目前,隐私计算技术标准化尚处于早期,行业的各项标准仍在制定过程中,其中头部厂商往往参与其中。未来会有更多的行业标准和管理办法,参与标准制定的厂商会得到更好的背书,对于服务大客户具有强竞争力。同时,隐私计算的产品及解决方案通过行业测评与认证,可作为判断厂商技术能力的标准之一。例如,中国信通院大数据产品能力评测、SDK信息安全认证等都能提供厂商产品与技术的直接证明。
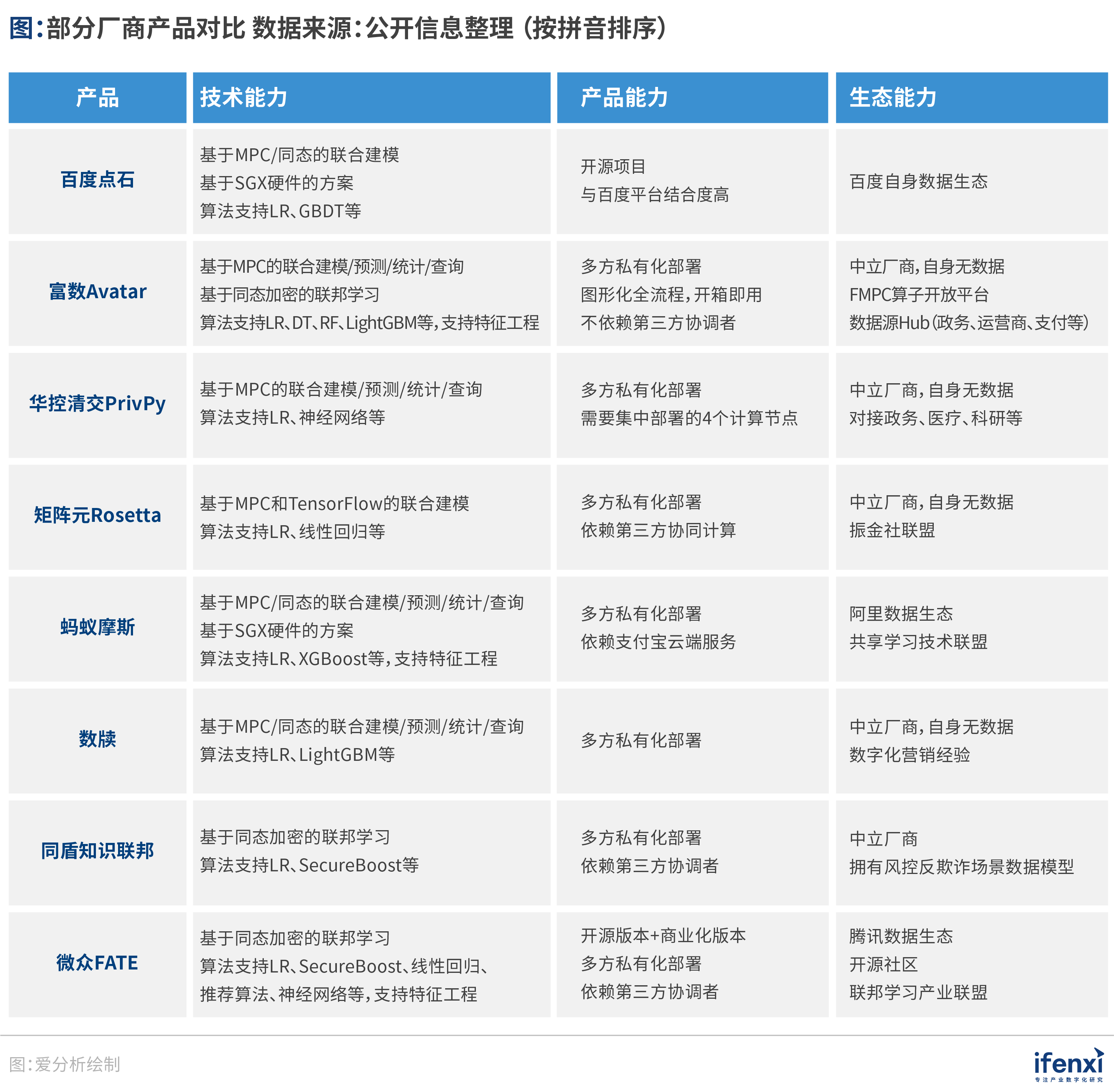
以富数科技为例,作为国内安全计算领域的代表性厂商,富数科技在密码学和机器学习领域拥有多项自主创新技术。
作为国内首批通过中国信通院安全多方计算产品技术评测的科技公司,富数科技同时也是国际IEEE联邦学习工作组成员、中国通信标准协会会员、大数据安全与流通标准组成员,并积极推动国内外相关技术规范标准的制定,包括《大数据基于多方安全计算的数据流通产品技术要求和测试方法》《基于可信执行环境的计算平台技术要求》《数据流通联邦学习技术工具技术要求》等多项国内领先标准。
富数科技自主研发的本地化安全计算平台Avatar,是国内首个企业级安全计算平台,现已获得信通院多方安全标准证书等国家及行业标准资质认可。目前该平台已升级至2.0版本,在应用层面实现巨大突破。
富数科技本身具有多元的科学家团队,包括分布式算法、加密算法等方向的知名专家。例如,华人IACR会士、国际著名密码学专家来学嘉教授作为富数科技特聘首席科学家指导其安全算法团队,在基于单向性好用难破的信息安全、隐私计算领域进行技术攻关。
富数科技VP卞阳表示,具体而言,富数科技的底层技术能力体现在几方面:一、速度快,通过底层算法自研优化,联合建模速度相比行业水平快3~5倍;二、技术全面,覆盖MPC、联邦学习和TEE可信执行环境,自主研发底层加密算子、分布式算法,实现上层应用,拥有强大的算法攻关实力;三、安全性高,支持无可信第三方的安全算法,突破了其他技术存在的局限性。
基于其强大的技术能力,富数科技已经实现了包括金融、政务等诸多领域的落地应用。除富数与交行、移动、电信联合创新的“基于多方安全图计算的中小微企业融资服务”外,富数与广州金控征信服务也已达成金融行业多方安全计算系统平台建设的项目合作,广州金控征信服务负责广州政数局政务数据对接,由富数提供底层多方安全计算核心技术产品和解决方案。
落地制胜,场景化应用能力成为关键
从企业客户的需求来看,客户需要的是基于隐私计算技术完整地解决具体的业务问题。这要求厂商不仅具备强大的技术能力,还能够针对应用场景需求给出完整解决方案,涉及技术的工程化能力以及技术融合。
基于隐私计算,厂商的工程化能力体现在几个方面。第一,验证系统的实用性,能投入实际使用之中;第二,实现系统易用性,保障计算系统简单易上手,厂商需要考虑密码学计算与大数据、AI框架的并行优化算法进行兼容,整体实现并行优化;第三,确保实际使用过程中的安全性,绝对避免数据滥用、误用的可能;第四,保障隐私保护技术的可拓展性,厂商需要设计良好的隐私计算框架,未来随着隐私计算的不断发展,能够不断集成最新的算法协议集。
同时,隐私计算的落地能力最终需要典型应用场景落地案例的验证,企业需要具备场景化输出能力。不同企业对于隐私计算的需求不同,理解用户需求并付诸实践,一方面考验了企业解决复杂问题的技术能力,另一方面考验企业的实施能力。在隐私计算起步初期,行业还无法提供完全通用于各行业的标准化产品,因此,企业的交付和服务团队是客户成功的重要支撑。
以富数科技的Avatar 2.0安全计算平台为例,Avatar 2.0集成富数科技多方安全计算、联邦学习、匿踪查询、联盟区块链等四大核心技术能力,可以实现完全本地化平台产品交付,解决包括本地化部署、联合统计、联合建模、联合营销、查询不留痕等行业需求。
在实用性方面,Avatar2.0对自身的联邦学习与多方安全计算(MPC)框架进行了更新与优化,用户和开发者可以基于底层安全算子库快速构建更多的隐私计算、联邦学习算法模型,央行监管沙盒项目的正式对外开放验证了其可实行性。
同时Avatar 2.0支持自定义算法组件和热插拔安全算子,通过国内首创联邦拖拽式建模,用户可在工作台画布上简单地拖拽各种资源、功能组件和算子,构建个性化建模流程,操作更便捷、自主性更高、流程更清晰,实现了产品交互体验的巨大提升。隐私计算应用实现从“Dos”到 “Windows ”的质变,重新定义一个联邦学习建模平台的概念——集成建模环境 IME(Integrated modeling environment)。
在安全性方面,Avatar 2.0 行业首创安全驾驶舱,将复杂的多方安全计算原理从黑盒变成白盒,实现安全可视化,提高安全的可解释性,让用户掌握更强的系统运营能力。同时,Avatar 2.0基于MPC的核心思想,从底层的基本算子和简易函数的计算开始,让参与各方完全直连,最终完成无第三方的产品升级。
除了产品化能力外,在场景落地方面,富数科技打造了强大的生态体系,与运营商、互联网巨头、国有大行等建立实质性的合作。
数据为王,生态协同决定隐私计算拓展边界
数据源是进行数据处理的基础,不论隐私计算的技术采用哪种体系,数据质量都决定了最终隐私计算最终的使用效果。但高质量数据资源是稀缺的,因此,获取高质量数据是隐私计算厂商的重要能力之一,高质量的数据资源能吸引更多的⽤户加⼊,不断贡献新的数据,具有较强的网络效应。服务好数据拥有方,让他们能够更好地对外赋能,是隐私计算生态建设的基础。
以隐私计算底层平台为基础,结合具有垂直行业解决方案和实施经验的厂商,共同在平台协作为多元客户解决问题,发展健康生态,最终决定了隐私计算厂商最终能够达到的边界。
因此,核心技术完全可控、业务场景落地流畅、形成数据网络生态,是隐私计算众多厂商的“试金石”,而未来,谁能够从中脱颖而出,也可以从这几项关键能力中看出些许分晓。
隐私计算未来趋势展望
中国的隐私计算发展具备一定优势,技术和产品正在逐步成熟,应用场景快速扩充,但仍然面临着一系列问题,行业整体处于起步阶段,仍具有较大市场空间。
在技术与基础设施层面,隐私计算效率容易受数据量和模型复杂度影响,数据质量不高。
在市场成熟度层面,用户对隐私计算的接受度还不高。由于隐私计算技术复杂且常常呈现“黑盒化”现象,大部分用户对隐私技术难以理解和信任。
但随着数据保护法规出台以及监管加剧,众多企业开始重视数据使用与安全,未来3年,用户对于隐私计算的需求将会进一步强化,企业需要服务更多的落地场景;而应用不同的应用场景,企业需要融合多技术体系,解决用户的复杂需求;同时,隐私计算依赖于多方协同,隐私计算技术与解决方案供应商更像一个中间平台,需要构建多方生态,以此形成隐私计算的规模效应。
标准完善,更多应用场景落地
隐私计算技术的行业应用才刚刚起步,目前法律、技术和数据的相关标准都不够完善,这也成为制约隐私计算发展的重要问题。同时,隐私计算主要的应用场景集中在金融、医疗与政务领域中,应用场景相对局限。
随着大数据产业的持续发展,企业对于数据的安全共享和应用的需求会进一步强化,延展至更多的业务场景中,隐私计算的落地场景会越来越多。
同时,隐私计算的产品与市场在迅速成熟,其解决方案、商业应用已经得到验证,企业正在探寻基于隐私计算的数字经济商业模式,将进一步扩大隐私计算的商业应用范围。
拓展应用场景的前提是厂商的系统和技术具有足够的“鲁棒性”,能够在不同的应用场景中保持同样的技术能力。
多技术融合创新隐私计算解决方案
从技术角度看,基于用户的需求演进,隐私计算不再局限于单一技术,而是融合多种技术路径和多项先进技术,包括密码学、人工智能、区块链等,满足用户需求。
首先,企业利用软硬件协同提升隐私计算性能。利用硬件能够加速隐私计算性能提升,例如专用芯片和控件的使用。
其次,隐私计算与区块链相结合,能够构建更加灵活的解决方案,提供数据共享的信任机制,保障隐私计算的不可篡改性、可验证性和数据的保密能力。目前有多家厂商在探索隐私计算与区块链的技术融合解决方案。例如,富数科技将联盟区块链技术与隐私计算的三类核心技术进行结合,用隐私计算实现多方计算,用区块链技术实现多方计账,利用智能合约来协调多方进行联邦学习。
最后,隐私计算将与大数据基础平台设施进一步整合,提供从存储计算到建模挖掘的全方位能力,提升产品的易用性。
多方生态构建,厂商协同解决用户更多需求
隐私计算涉及多方企业数据共享,一方面,数据具有很强的网络效应,数据融合能够产生“1+1>2”的效应,因此需要多方企业共享数据;另一方面,数据公司、传统企业、云厂商等企业存在各自的痛点,单一厂商无法覆盖用户的全部需求,隐私计算需要多种技术与解决方案解决用户的多元需求。
因此,隐私计算平台涉及多方生态的协同合作,包括数据资源型公司、技术公司、具有大量数据应用场景的公司等,覆盖数据联通生态、数据与人工智能算法的联通生态以及数据提供方生态。建设大数据安全计算生态,实现跨行业、跨场景的合作,融合更多的数据、技术与场景,才能推动更多的场景落地,有利用弥补彼此的短板,实现可行的商业模式。