
- 数据智能

近日,爱分析在京举办了2019爱分析·中国人工智能高峰论坛。爱分析邀请了九章云极 CEO方磊进行了题为《数据科学平台赋能传统企业》的主题演讲。
方磊讲解了数据科学平台的含义,用途,落地案例以及未来发展方向等内容。
现将方磊的演讲实录分享如下。
方磊:谢谢大家,谢谢爱分析的邀请。今天和大家分享数据科学的背景情况,以及怎么帮助企业实现企业级AI的案例。
在数据上直接加载算法,是数据科学平台的核心
这张图是中国大数据的图谱,今年有了一些变化,在左下角出现了数据科学这么一个领域,这个变化让我们很开心。因为不仅我们在这个领域之内有一席之地,更重要的是从平台这个层面,数据科学在整个生态里也牢牢地占据了一席之地。

什么是数据科学?数据科学的逻辑在哪里?和机器学习,深度学习着怎样的关系?今天我就给大家介绍一下数据科学。
我认为数据使用分为四大方面,分别是数据科学及机器学习平台、BI及可视化、数据仓库和数据治理,我们分别来解释一下。
数据仓库包括数据中台的建设,解决的是集中化的存储问题;数据治理解决的是数据格式意义的问题;关于BI及可视化,我们都知道有很多业务的数据是很难理解的。举个例子,计算一家保险公司的客户数量可能不是一个数字,因为投保的人和理赔的人并不是同一个人,会导致投保和理赔的部门理解的“客户”是不一样的。。当你理解了你的数据,用BI给决策者和运营人员看这个数据结果,这就是BI及可视化。
最后是数据科学和机器学习平台,与前者的区别简单来说就是一个是将客观事实展现出来,由你来做决策,另一个则是自我训练模型,由模型直接决策。
刚才主持人提到2017年Gartner做了数据科学的象限,这个象限很简单。数据科学是一个比较大的范畴,其核心是各类数据以后会使用算法加载到数据上解决具体业务问题。有很多算法甚至都无法称之为人工智能算法,比如说关于资产配置的组合风险评价,这些都不属于机器学习的范畴。
在数据上加载算法,这就是数据科学的核心
对数据的分析经历了1990年前后的基础数据存储到2000年基于数据仓库BI的探索,再到2015年经过增强分析年代,核心就是围绕数据科学,利用算法在数据上进行更深度的分析。
再看一下国外厂商在数据科学领域的表现,其中有一个叫alteryx的上市公司很不错,还有两个分别是Dataiku与DataRobot。
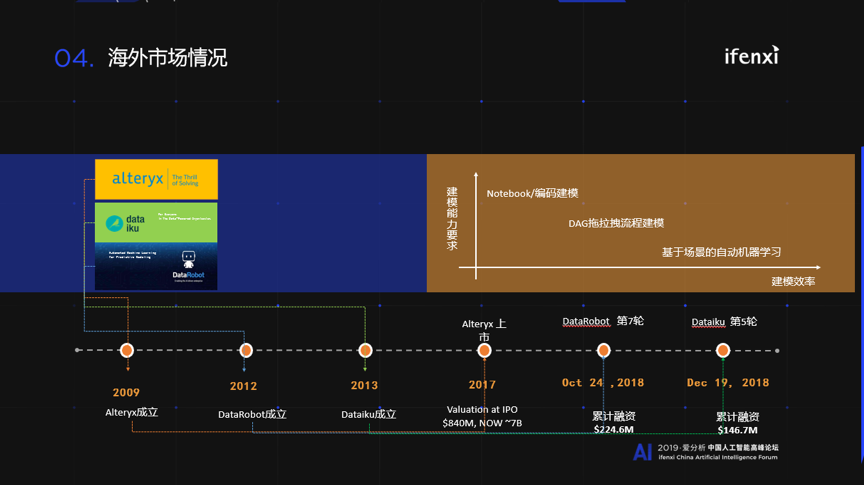
作为数据科学厂商,我刚才说了核心是数据上加载算法,你的产品形态体现为建模平台,所以建模能力的要求就很重要。构建AI的方法有很多种,最开始出现的是写代码,我们称为编码型。第二种,因为水平差一些写不了代码,那就预先写好一些代码再配置一下,这个叫可视化编程,通过拖拉拽解决问题。第三种,是给数据自动生成模型,什么都不管,这叫自动机器学习。以上这三种方法不断降低企业AI构建的门槛,整个行业的发展方兴未艾。
“工具”、“平台”再到“大脑”,让企业越来越智慧
具体落地肯定也有很多挑战,说前景的时候比较容易激动,说落地的时候肯定也是很有压力的。第一个挑战就是技术发展太快,我们都知道今天的AI技术层出不穷,应接不暇,学都来不及。第二点,建模的困难度导致对人力依赖很大,如果你有优秀的数据科学家,你要珍惜,千万不要让他被挖走了。企业的模型管理水平也还处于早期,对模型生命周期的管理不健全,模型的稳定性和生命周期管理都是非常空白的。
关于模型管理,能找到的最新的公开文献是2011年的美联储的监管文献,从2011年到今天,十年的时间都找不到一篇关于模型管理的权威文献,这种空白也是一种挑战。另外,资产的积累也是非常困难的,你的人员,新的AI创新的组织怎么积累。
我们有几个思考,第一个是开放性和封闭型的思考,第二个是如何建立有效的模型,第三是关于工具和平台的思考。
关于工具和开放已经是个老话题了,大家都很熟悉技术栈,包括我们中间件的框架都在改变。数据科学对于以前大家比较熟悉的SPSS,SAS这样一些分析软件也从封闭式的软件走向开放,所以开放是一个大潮,势不可当。
我们为什么要开放呢?举一个例子,因今天很多人讨论NLP,对于自然语言的处理,我们经过了很多模型,最近几年更是加速迭代。有一些新的技术,你发现性能是一个指数级的增长,如果你不是开放式的平台是非常难以涵盖的,所以这对很多企业来说是非常大的挑战。大家知道架构师的工资更高,因为写个好的架构比写一个好代码更重要。
什么是开放性的架构,我们总结了几点,第一点是能跑各种各样的环境,我们知道数据科学家会用很多语言,对于不同的语言、框架、环境、服务,甚至最后支持的硬件都要做非常开放式的支持。我们碰到的客户有一些专用的各种XPU,各种各样的加速器都会使用,尽管很多加速器未必是标准的。使用各种各样的算力和加速器,一定要保持非常开放的架构才能容纳计算架构,包括模型服务。而且模型服务这个生态里有非常多的公司,很多服务是应用厂商开发的,很难对他做统一的管理,很多模型做出来,甚至不是主流的深度学习框架训练的。

我们碰到过这样的客户,他们用了一些更先进的,基于可解释性更强的贝叶斯编程模型,这样的模型运行和现在主流模型是不一样的,你怎么提供一个框架支持他。对于编码的方式,建模的方式怎么打通,自动机器学习最方便,同时也最受限,这些东西怎么放在一起进行转换,都是你在构建自己的数据科学系统,或者是数据科学团队的时候要思考的问题。
平台和工具的选择方面,很多人问我是不是开源就足够了,这是分阶段的,当你还在第一阶段,使用开源工具很多情况是满足需求的。下个阶段,使用机器学习的算法解决业务问题。当你解决业务场景就要从开源技术走向工具,因为你面临着模型的部署、上线、监控,全生命周期的管理,当你从一个智能场景走向多场景的时候,必将面临大规模的模型服务的性能和稳定性问题,可扩展性以及团队协同工作的问题,你要做一个智慧营销2.0,有十几个场景一起做,一定从工具上升到平台。
再往前走是什么?从平台上升到所谓的大脑,有更多的外部数据,外部模型,供应商和咨询公司都能给你提供,不只是一个大场景,也不只做营销,还可能做各种业务。所以我们给出个线路图,我们认为开源技术是开放性的根本,同时我们看到一个报道,70%关于数据科学和人工智能解决方案都是基于商业软件开发的,这给我们发出了一个信号,商业软件领域还是大有可为的。
全世界都在降低壁垒,未来是知识融合
为什么持续性地降低壁垒,壁垒到底体现在哪里?数据科学大军中有不同的人,包括业务分析师,数据科学家,还有模型与算法运维工程师,这些人要懂机器学习,懂得写代码的话,这个要求就太高了。不同岗位的人有不同的职位需求,他们会使用不同的技能,确实需要提供一个工具集,甚至是一个平台,帮助他们完成他们的使命。
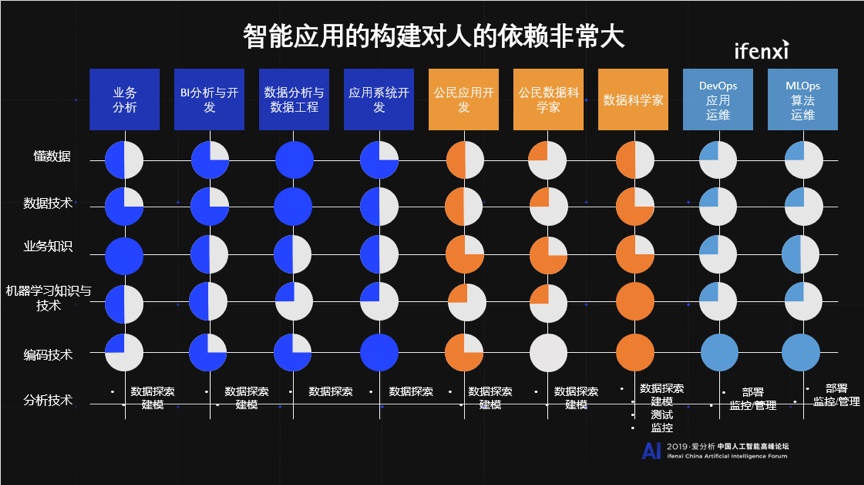
大图的意思,包括上文提到的美国的三个公司,他们持续做了一件事情就是降低壁垒,也是我们做的事情。降低壁垒之后是什么呢?我们的判断是要解决知识融合,因为降低壁垒是指让技术变容易,容易之后最重要的是取得业务价值,关键是知道使用新技术帮助我增加了多少营收,减少了多少损失。进入业务之后就会发现有非常多的业务需要支撑,上一位嘉宾讲知识图谱讲的很好,当你要解决具体业务问题时不只需要机器学习算法,也需要使用知识图谱,也需要使用数据中台,八仙过海才能把业务解决好。
之前一个嘉宾也提到了,做视觉检测,我们也有客户解决这样的需求。而九章不太一样的是我们自己做的比较聚焦,我们提供数据科学平台和模型,整个系统最终由合作伙伴给客户交付。大的逻辑和大家看到的很多情况类似,我们也能看到数据科学平台做的数据+算法这个事逻辑很清晰,有很多数据和图片,我们加载一些算法,这里面使用了深度学习的能力,让我们可以在每条产线上训练出来更适合产线的模型,进一步提高准确率。
最后提一下数据科学平台肯定有未来,它将会带来很多新的趋势,低成本,低使用门槛的情况下,大家的需求是更加标准化的产品,而且非常强大的自动机器学习。即使我要开发,也希望是有低代码的,可视化的开发能力。
积累效应上,所有的人都希望自己的产品、平台、自己开发的系统,比如场景仓库,算法仓库,能够拥有一些积累效应,另外还有知识融合积累你的业务知识,总而言之是个积累,让你可以更好地进行扩展,重复使用。
还有一个具有网络效应的就是联邦学习,我们现在很多时候对数据抓的很严,不能交换数据了。我们能看到一个银行如果想在自己已有客户中推荐基金,就希望使用基金公司的模型,因为基金公司有几千万的客户,他知道什么东西卖给谁更合适,但是卖还是只能通过银行卖,那就没法直接使用基金公司的模型。这个里面有很大的市场需求,可能会使用联邦学习的技术。
将来可能会进入一个时代,大家都通过训练自己的模型,并且交换一些模型的部分,这样的场景将会在不就的未来成为现实。
这是我今天的分享,谢谢大家。

