
- 数据智能
|编者按
在2021年底,我曾应科技媒体InfoQ的邀请,总结了2021年的数据平台架构(详见:解读数据架构的2021:大数据1.0体系基本建成,但头上仍有几朵乌云),提出了的2021年的5个热点、4个趋势和3个挑战。在过去的两年,数据架构领域发生了很多重大变化(很多是拐点级变化),例如大模型技术突破、向量检索成为热点、半/非结构化类Dark Data开始被关注等等。作为数据平台从业者,我经常被问到“下一代数据平台发展趋势?”或者“AI平台和数据平台是否应该一体”等问题。我想这是一个很好的时间点,谈谈对数据平台发展趋势的判断,特别是当AI这样的“完美风暴”来袭之时,数据平台该做怎样的选择,停泊在港口躲避,还是尽快入局追风而行?
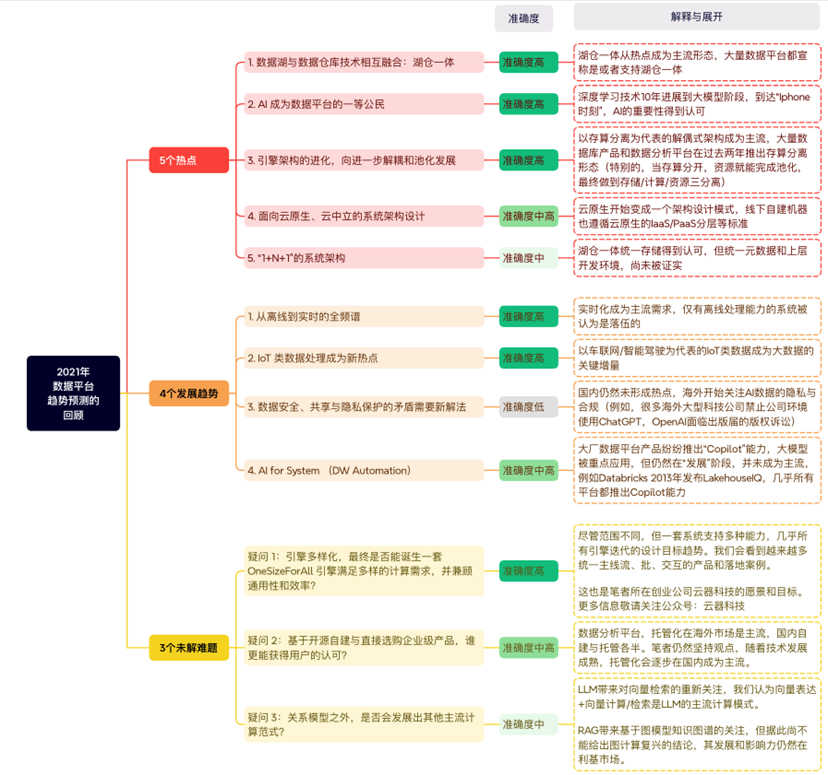
图1 对“2021年数据平台趋势预测”的回顾
2024年,数据平台领域发展到哪一阶段
数据架构自70年代由关系型数据库开始发展,前后经历了三个阶段:
- 数据平台最早来自数据库技术,1970年关系型数据库发布,以事务数据处理技术为主,以Oracle,SQLServer为代表,已经发展50年。总体市场规模最大,增长放缓。
- 数据平台二次革命来自大数据技术,2000年因大搜索需求提出(规模带来质变),并进化成数据平台0,以大规模数据分析技术为主,以Snowflake/BigQuery/Hadoop体系为代表,已经发展20年。总体市场规模中等,增长仍然迅速。
- 第三次革命来自AI(深度学习/LLM)带来的突破(规模带来质变),扩展能处理的数据的种类(从结构化,到半/非结构化),也扩展计算引擎(从关系型数据分析计算到基于大模型的内容理解与逻辑推理)。

图2 数据平台发展三次革命
数据分析领域仍然保持增长,但产品/厂商逐步收敛。AI成为数据架构的新驱动力
一项技术是成功还是失败,关键期往往在低谷期到普惠期之间,一旦进入成熟期,它会以普惠产品的形态保持持续的发展。因为已经被普遍采用,变成事实标准,在没有跳变类技术出现的情况下,会一直发展下去。我们身边的内燃机技术、移动通信技术、数据库技术等都持续发展。
但相比数据库技术,大数据技术处在成熟早期,仍然有较大市场空间,并保持高速增长。上图同时对比了数据库领域的领军企业Oracle和大数据领军企业Snowflake,成立46年的Oracle在2023年有20B$的营收规模,是成立12年的Snowflake 2B$营收的20x,但Snowflake有50%的同比增长率,是Oracle 5%增长率的10x。如果双方保持当前增长率,Snowflake会在7-8年后超越Oracle。
相比2021年火热的数据类新公司成立和融资(2021年Kafka背后商业公司Confluent上市,Clickhouse、Iceberg商业公司成立,Databricks7月内两轮融资26亿美元),2024年数据平台领域投资趋于冷静,厂商和产品逐步开始收敛,这也带动了技术架构的收敛(下节展开)。
数据分析架构趋同,但Lambda架构远不够完美。数据AI架构新兴,高速迭代中
大数据技术为代表的数据分析架构发展20年,总结当前典型的数据平台架构是计算部分采用Lamdba架构,存储层由数据湖或者数据仓库构建。AI相关组件尚在发展成熟中,没有确定性的架构。
以下通过几个不同场景不同用户的数据架构实例,来总结当下数据平台的典型架构:

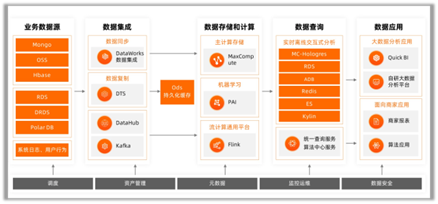
图3 目前典型的大数据系统架构案例
数据分析部分架构趋同,从数据采集开始,到多种不同的存储体系,再向上形成了“离线计算”和“实时计算”的两种计算模式,最上层是数据的消费部分,形成“交互分析”的计算模式。特别的,医疗系统的案例中,存有大量图像与视频数据,因此整个架构的底部会有一层面向非结构化数据存储的存储体系,以及右侧还有面向医疗领域机器学习的智能图片识别能力。
基于上述,我们将当前数据平台简化为如下典型架构图,其中“不变”的部分用黑底来表示,“变化发展”的部分用灰底来表示,如图下可见。
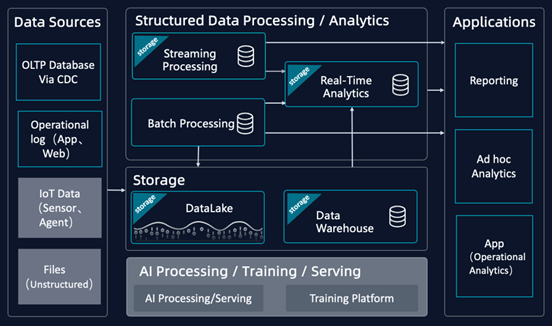
图4: 当前数据平台典型架构图(简化版)
鉴于数据平台整体分成分析/AI两部分,且两部分的发展阶段不同(数据分析平台进入成熟期,数据AI平台刚起步),因此后文分开阐述这两部分。
数据分析领域的三个趋势
当前数据分析平台的典型架构是Lamdba架构(由三层系统组成:批处理BatchLayer,流处理层SpeedLayer,服务层ServingLayer),随批、流、交互三种引擎诞生和成熟组装而成。其本质是通过三个不同的引擎分别满足数据三要素(性能、成本和数据新鲜度)设计方向。每个引擎向单一目标优化且优化方向各不相同(如下图),但组合起来就形成整体架构缺陷。其主要缺陷包括如下几个方面:
- 组装式数据架构复杂 - 整个平台包括多种引擎,不同引擎可能自包含存储和元数据系统,导致整个系统存在多套异构存储,多套元数据,带来大量的计算和存储冗余和管理成本。极高的数据管理成本和开发成本。
- 存储层,数据湖和数据仓库尚未真正统一。受多种引擎/多套异构存储影响,真正的湖仓一体很难在Lambda架构下实现。
- 组装式数据架构缺乏满足业务变化的灵活性。多种引擎的接口、语法、语义均不统一,做不到无缝切换,调整业务逻辑代价高。
笔者认为,数据分析领域的三个发展趋势,与上述缺陷密切相关。
趋势一:计算引擎的一体化
组装式 Lambda 架构存在的问题是业界普遍有深刻体感的,为了解决上述Lambda架构的问题,业界很早就提出Kappa架构的概念,并一直寻求一体化的实现和产品。很多已有产品也都曾经尝试过一体化的方向(例如Apache Flink提出的“流批一体”概念和实现,Google BigQuery推出BIEngine尝试离线实时一体化的方向)。应该说,“一体化”是数据分析领域长久以来的趋势共识。
但截至到目前,都不是很成功,为什么实现“一体化”的架构那么难?这主要有两个原因:批、流、交互计算的计算形态不同,优化方向也不同。如果“批、流、交互计算”三种传统计算模型均不能完成计算引擎的统一化,就需要新的计算形态来统一。
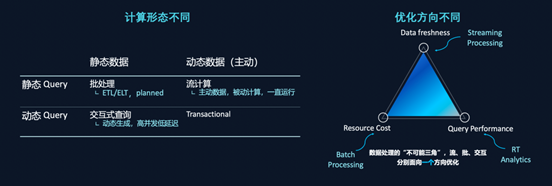
图5: 批、流、交互三种计算形态的差异
从工业界的角度看,2022-2023年,Databricks基于之前的Delta Table和Live Table提出统一的Delta Live Table的概念和实现,Snowflake提出Dynamic Table的新概念,当前处于Preview的阶段,均是为了实现流批统一。2023年,笔者所在的创业公司“云器科技”提出基于“通用增量计算(Generic Incremental Compute, GIC)”新计算形态,致力于用于构建一体化引擎(Single Engine)。受限于篇幅原因,对计算形态统一的细化分析以及新的计算形态选型和能力评估,在此不再展开,读者可以参考这里了解更多细节。
趋势二:湖仓一体成为主流架构,Iceberg成为事实标准
湖仓一体(Lakehouse)的概念最初由Databricks在2019年提出,经过4年的发展,已经成为主流架构。(湖仓一体的概念和详细介绍可以参考笔者的另一篇文章)。
当前,湖仓一体概念得到认可,但架构实现仍然多样。实际上湖仓一体架构两个流派,第一个流派是以数仓这种方式诞生的,它是一个左右派,左边是一个数据仓库,右边是一个数据湖,中间以高速网络相连形成联邦查询能力;第二个流派是从数据湖向数仓演进,整体架构是在数据湖上搭建数据仓库。这两个流派的代表分别是 AWS Redshift/ 阿里云 MaxCompute,以及 Databricks,目前这两个流派都还在发展中。在2023年,为了统一湖仓一体的架构,部分企业提出“湖仓一体”的设计标准,例如偶数科技提出ANCHOR的标准,Databricks提出Open、Unfied、Scalable三标准等等。

图6: Lakehouse架构演进
目前公认的设计标准总结为如下三条:
- 一套数据,统一的元数据中心,具备*一致*性(其他层次上的数据用Cache抽象)
- 开放性,数据格式公开可访问
- 可插拔性,上层引擎/应用可以灵活的插在Lakehouse上(这对于新兴的AI引擎/应用至关重要)
数据的开放性是标准的核心,它同时被数据格式决定。最初的数据湖仅支持简单文件格式,目前Apache Parquet和Apache ORC是文件格式的事实标准。但单纯的文件很难表达复杂的表特性(例如对数据更新的表达),作为数据湖向湖仓一体的一部分,这就有了数据湖表格式,过去几年诞生了Apache Hudi、Apache Delta、Apache Iceberg三种标准。2023年下半年,Snowflake/Databricks同期宣布旗下数据平台支持Iceberg的湖仓架构,至此数据湖三大表格式的争论告一段落,Iceberg开始成为事实标准。但Lakehouse上的统一元数据模块部分尚待挖掘和整合,Databricks的UnityCatalog是一个好的参考。
趋势三:“云原生”从云的概念变成一个架构设计概念
云原生的概念随云计算诞生,最初是云计算概念的一部分,特指针对云的特点设计的架构能力。过去20年云计算的发展推动了包括大规模存储、虚拟化技术和大规模网络技术的发展,也极大的影响了软件架构的设计。
如下图所示,系统和软件架构呈现横行分层发展的趋势,并逐步切换出更多的层次,带来更低的开发成本和更好的资源共享能力,当前的应用开发者仅仅需要关注数据和应用逻辑即可。
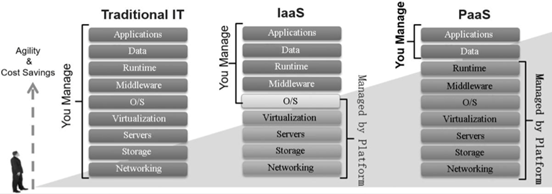
图7:系统和软件架构呈现横行分层发展的趋势
上述架构演进不仅仅影响云,“云原生”从云的概念变成一个架构概念。私有化部署和本地IT开发也遵循“云原生”架构。例如:
- 存储/资源/网络的统一化/池化
- 存算分离
- 计算资源共享(混部)
- 应用的微服务化和无服务化
数据平台,处于系统架构的PaaS层,“云原生”也成为标准设计模式,对下依赖IaaS能力,对上与客户应用解耦。新一代的计算平台基于“云原生”架构设计更符合发展趋势。
同时,每个层次开始标准化(例如IaaS层)并各自进化。模块间进一步解耦开,并在能力/效率/成本上独立持续进化。例如:AWS2023年推出S3 Express OneZone,提升10xIO延迟的同时降低40%的成本。VastData推出基于NVMe over Fabric的分离式全共享架构存储,提供了大规模可扩展性和强大性能,并降低存储成本。这些能力进化既有独立厂商推动,也有云厂商推动。考虑到云厂商在IaaS层和部分PaaS层的规模效益(规模、业务量、投入),公共云平台持续带来更高的性价比。尽量下云VS上云的争执一直持续,从2024年看,选择公共云是绝大多数公司的选择,“下云带来高性价比”仅对于规模在百亿美金以上的公司才是真命题。
数据AI平台领域的三个展望
随OpenAI在2022年底发布GPT3.5,大模型和AGI开始得到广泛认可,企业对这个领域的投资开始大大加速。“Data Centric AI”概念开始进入大家的视野,稀缺、优质的数据成为AGI时代最大的Differentiator。这主要是因为:
- 在AGI三要素:模型、算力、数据,前两者高度同质化,数据是最大的变化。海量+高质量数据,是预训练模型效果的前提(包含各种行业模型,比如BloombergGPT针对新闻财经类)。很多国内基础模型厂商尝试在中文这一特定领域形成针对ChatGPT和原生Llama模型的差异化竞争力。
- 私有数据的有效组织和管理,是模型最终落地到企业的前提(构建RAG的核心)。企业核心的经营数据和文档天然具有高度保密性,只存在于企业的私域环境中,同时因为这一类数据具有强认证和权限管控特性,并不适合Pre-train或者Fine-tune到模型中(即使模型是私有部署的,也不能满足安全需求),所以构建企业私有知识库是AGI落地企业的关键一步。实际上,数据平台本质上就是企业私有知识库的一部分,但主要存储和处理结构化数据,在AGI时代数据的种类和处理能力将被极大扩展了。
- 基于数据的AI训练/服务过程,大多数工作仍然是传统数据处理,模型训练仅占一部分。下图是对AI全流程task的统计,大多数task都是数据处理。

图8: AI全流程里面,数据处理占据大量比例
基于上述,我们给出面向未来的数据AI平台的三个展望。
展望一:数据与计算的关系从1:1向3:N演变
数据库和数据分析平台,尽量引入数据湖以及NoSQL的能力,其重点仍然是存储和计算结构化数据(Aka可以被结构化的数据表格),存储与计算被认为是1对1的。而最近十年,特别是随着深度学习技术的发展,ML/AI 拓宽了数据平台需处理的数据类型,底层引擎模式随之改变:
- 改变一,引擎以往只能处理结构化数据二维表,现在可以通过 AI 处理包括 text 、json 在内的半结构化数据,以及处理非结构化数据(音视图数据);
- 改变二,引擎模式的顶层计算架构也在改变,类似生成式AI对文本和数据的直接理解和解读,类似code interpreter通过理解数据语意做大模型的插件式、多语言融合式查询分析,是除SQL的二维关系表达和分析引擎外,将AI的计算能力纳入到引擎。

图9: 数据平台架构从一对一演进到三对N
这种架构演进,也回应为什么数据湖/湖仓一体成为主流架构,以及数据开放性变得至关重要。
展望二:*部分*数据架构重回搜索架构时代
前文已经论述的企业私域RAG产生的原因和必要性,达到一定水准的RAG是大模型落地的必选项。相比数据库或者数据仓库,RAG实际上是个更大的概念,面向未来看,所有数据都可以被抽象成知识库,结构化数据和分析仅仅是RAG的一部分。
而RAG的数据平台构建,与搜索引擎原理和流程非常类似。下图左右分别展示大模型+RAG架构链路和搜索引擎架构链路。对比会发现,流程非常相似,
- 相似的流程:“收集>索引建立=>索引服务=>召回=>排序=>处理=>输出”
- 相似的核心指标:Relevance(相关性)、召回率(Recall)和准确率(Precision)当作最核心指标。性能是基础指标但不是最关键的。
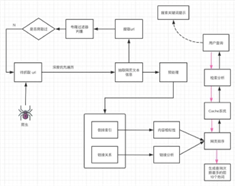
图10: 数据平台架构从一对一演进到三对N
大数据时代,搜索对数据平台架构带来革命性的影响:
- 10X-100X的数据量,带来分布式化和低成本,Scale-out成为主流
- 传统数据库对ACID/transaction的要求被放松,不关注严格建模,数据的存储和处理都更粗放
- 大量Impretive编程模式被引入,Dataframe、User-Defined-Function(UDF)被大量使用
数据AI时代,通用RAG的需求将重塑数据平台,并将(部分)数据平台架构转型搜索/推荐模式。
特别值得一提的是,最近有个问题被反复问到:数据处理/分析平台和AI平台是一体的还是割裂的?回顾历史,是搜索需求驱动了大数据平台的诞生和发展(数据平台的第二次革命),但搜索平台与数据平台从来都是一体的,就用阿里巴巴为例,阿里所有的数据(包括搜索/推荐日志)都汇总进数据中台,统一处理。搜索推荐业务是数据中台业务的一个分支,是生长在数据平台之上,其数据处理、搜索/推荐算法也跑在数据中台的数据上。仅有在线服务部分(索引召回、排序)是与在线服务一起。因此,我们可以通过类比传统搜索平台来回答上述问题,数据平台和AI平台自下而上是一体的,仅有上层应用不同会差异。
展望三:增强元数据(Augmented MetaData),重要性提升10倍,构建难度也提升10倍
Dark Data是Gartner提出的概念,用来指代数据资产里面没有被利用起来的部分。在数据库和数据平台发展的50年历史里,关注点都在结构化数据上,占比更高的(普遍认知是80%)的半/非结构化数据被认为是DarkData。之前传统深度学习带来的NLP和Image/Vidoe Recognition能力(DL2Tag)仅能做到识别,理解深度不够。最近1年的大模型能力提升,使得半/非结构化数据有机会被理解和使用。一句话总结趋势:Dark Data (80%) can be bright。
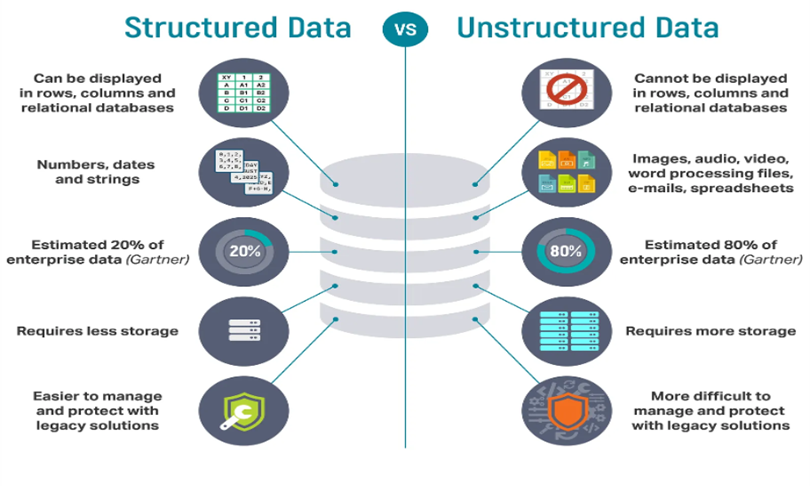
图11: 非结构化数据通常被划分为DarkData
但半/非结构化数据的信息抽取、管理和使用,面临很多不同的挑战:
- 半非结构化数据,知识抽取和理解困难且昂贵,大模型的推理速率和带宽远达不到普惠的水平
- 用户知识库(RAG)是个大概念,包含结构化、半结构化、非结构化三类数据。结构化数据不应该被忽略(比如用户报表数据),但目前RAG+LLM和数据分析割裂。
- 向量表达做到了多种模态数据到数学表达的统一(用Vector表达所有数据),因此VectorSearch+LMM 成为当前流行架构,但仅有向量检索并不足够,向量检索仅能回答相似度的问题。
从架构角度看,存储层,三类数据的存储可以被湖仓一体架构天然统一,计算层 ,关系计算与大模型计算模式和原理不同因此无法统一,但计算结果可以通过混合向量+标量+标签的方式统一起来,在后面做融合计算。增强元数据层(Augmented MetaData)是三类数据被发现、并融合计算的核心,也是整合的关键,但难度巨大:
- 三类数据融合后,数据量提升一个数量级
- 结构化数据本身已经是Schematized,元数据表达简单低成本,但半非结构化数据很难直观描述,如何抽取、如何表达都难的多
- 结构化数据上常见的数据安全、数据治理与访问控制,同样适用于三类数据,而面向AI的governance是摆在从业者面前的显著问题。
增强元数据领域,在过去两年有很多投入,微软大力推动Data Fabric,试图打造“一个 AI 支持的分析平台,可将你的数据和服务(包括数据科学和数据湖)整合在一起,从数据中获取更多价值。”。Databricks推动Unity Catalog,目标是“Unified governance for data and AI”。我们相信这一领域在未来会成为趋势和热点。
三个未解的难题
如上所述,数据分析领域保持高速发展,数据AI领域有革命性变化。在笔者看来,有如下未解问题摆在从业者面前。
疑问 一:SQL VS Python,当自动代码生成成为主流,赢家会是谁?
SQL作为关系型数据分析计算的官方语言,是数据库时代的唯一编程标准。到了大数据时代,从MapReduce开始,到Spark DataFrame,Java/Scala/Python成为数据分析编程标准的挑战者。但在数据分析领域,SQL以声明式编程语言(Declarative Language)天然的易用性和普适性最终保持了主流编程语言的地位,Spark/Flink等大数据处理平台最终都增加了SQL接口,新一代数据平台Clickhouse/Snowflake等仅支持SQL。
但随着大模型/AGI发展,编程开始走到辅助编程(Copilot)阶段,最终会发展到全自动代码生成的阶段。编程接口最终不再面向人而是面向模型和Agent,这种情况下SQL的劣势开始逐渐显露出来,例如SQL编程自解释能力不足,需要依赖更多外部模块(比如元数据系统),表达能力受限等等。笔者经验也印证,同样的RAG+Prompt能力,大模型生成的Python代码质量高于SQL。
特别值得一提的,Databricks在2023年推出English SDK for Spark的能力,得益于Spark广泛可获取的资料,在不需要额外RAG和Prompt的情况下,直连ChatGPT4即可获得不错的编程效果。概念和能力都给业界带来启发。
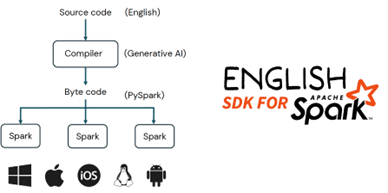

图12: 以自然语言为编程入口的架构和例子(by Databricks)
疑问 二:数据平台的“自动驾驶”多久能实现
AGI在重塑搜索、内容生产、辅助编程、智能客服等多个行业和领域。数据相关领域也有智能化的巨大潜力。AI4Data的概念已经被提出多年,在数据库顶会SigMod21上的论文《AI Meets Database: AI4DB and DB4AI》对这个领域做了详细的阐述。
但多年来,数据开发和数据应用开发仍然以人工的方式为主(如下图)

图13: 我们好奇并期待:何时AI能够让数据平台进入“自动驾驶”时代?
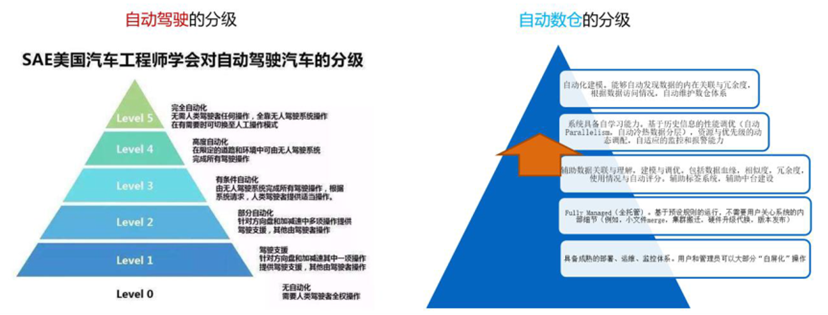
图14: 类比自动驾驶,自动化数据平台的一个分级
疑问三:谁会成为“第六大数据平台 The sixth Data Platform”?
过去20年大数据技术的兴起和高速发展,诞生了当前的“五大”数据平台供应商:亚马逊(Redshift为代表技术)、微软Azure(Azure Synapse为代表)、谷歌(BigQuery为代表),以及Snowflake和Databricks。他们是当下的Big Five。
进入AI时代,我们坚定的相信,新一代数据平台会涌现出来,他们可能来自BigFive自身的迭代,也可能来自新兴创业公司。新技术带来新的机会,并持续塑造新商业。让我们期待第六大数据平台在不远的未来诞生。
笔者大胆预测,新一代平台会具备如下5个特性:AI Native、Data+AI Converged、SingleEngine For Analytics,Lakehouse and Cloud Native.
|写在最后
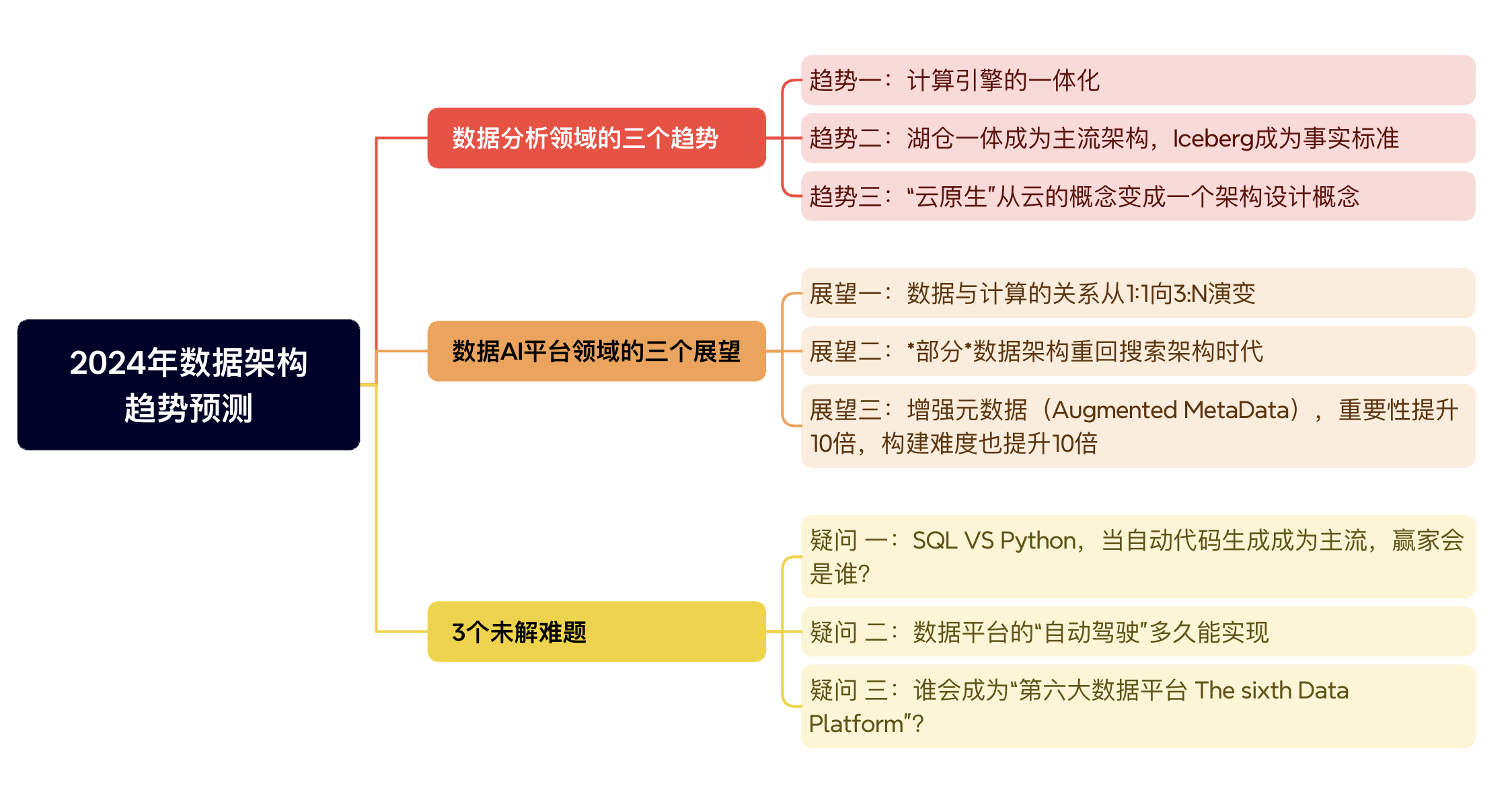
图15:2024年数据架构趋势预测总结