
- 人工智能
- 企业服务

编者按
问题的语义等价判断是智能对话系统中的典型难题,百分点认知智能实验室提出了一种新的问题语义层次匹配模型,该模型借鉴了域适应的MMD思想,创新的结合了BERT时代的预训练模型和BIMPM上层架设网络,通过抽取语言模型中不同层的表示而达到更好的效果。在公开的Quora和SLNI两个数据集上分别进行实验,该模型的效果都达到了目前的State-of-the-art。
智能对话系统因其巨大的潜力和商业价值受到越来越多研究者和从业者的关注,对话的主要种类包括闲聊型、任务型、知识型、阅读理解型等,目前已经广泛应用在智能客服、智能音箱、智能车载等众多场景。
近年来,智能对话还出现了新的应用场景,例如可以将自然语言转换为各种程序性语言,如SQL,从数据库中找到相应的答案,让用户和数据库的交互变得更加直接和方便。
问题语义等价的重要性
简单的看起来,似乎只需要判断两个句子的相似度,例如其重合词语的个数即可以解决。但事实上,判断句子是否等价的任务要远远比单纯的词语匹配复杂。举例来说,问题“市政府的管辖范围是什么?”和“市长的管辖范围是什么?”仅有两个字的差异,但两者语义是不相同的,因此其回答也应该不一样的。另一方面来说,“市政府的职责是什么”和“请问,从法律上来讲,市政府究竟可以管哪些事情“这两个问题,除去在“市政府”一词外,几乎是没有任何重合的,但两者语义是等价的,因此其答案也应该是一样的。
从这几个例子来看,句子匹配的任务需要模型能够真正理解其句子的语义。而今天我们所介绍的模型就是如何让机器更有效的理解和分析两个句子的含义,并进行语义等价比较。而我们采用的方法借鉴了MMD在图像处理时用到的深度匹配思想,并将此思想运用在了BERT多层网络模型上。
基于BERT和BIMPM的问题语义等价新模型
在BERT等预训练模型出现之前,语义本身的表达一般是用word vector来实现。为了得到句子的深层语义表达,所采用的方法往往是在上层架设网络,以BIMPM为例,BIMPM是一种matching-aggregation的方法,它对两个句子的单元做匹配,如经过LSTM处理后得到不同的time step输出,然后通过一个神经网络转化为向量,然后再将向量做匹配。
下面来详细介绍一下BIMPM的大体流程,如图中所示,从Word Representation Layer开始,将每个句子中的每个词语表示成d维向量,然后经过Context Representation Layer将上下文的信息融合到需要对比的P和Q两个问题中的每个time-step表示。Matching Layer则会比较问题P和问题Q的所有上下文向量,这里会用到multi-perspective的匹配方法,用于获取两个问题细粒度的联系信息,然后进入Aggregation Layer聚合多个匹配向量序列,组成一个固定长度的匹配向量,最后用于Prediction Layer进行预测概率。
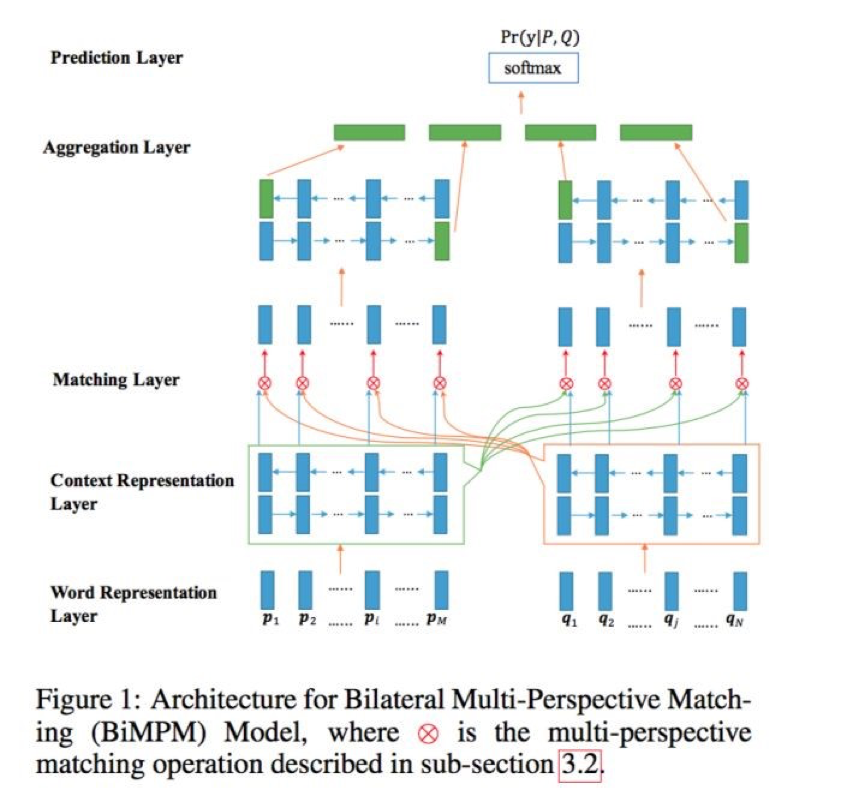
如果我们将MMD的思想应用到句子匹配的任务上,并用BERT预训练深层模型来实现,就会得到一个重要的启发,MMD思想的主要效果来源于它将BERT预训练深层模型的不同层表示进行匹配,形象地来说,这是一种“向下匹配”的思维。而BIMPM由于在BERT之前出现,其语义表示只能通过词(字)向量和LSTM等网络进行,因此它捕捉特征表示的方法只能通过“向上匹配”。这是否意味着自从BERT出现以后,将这两种方式进行结合呢?
基于这个思路,我们在本文中提出了问题语义等价的层次匹配模型,它的思想是将特征“向下匹配”和“向上匹配”相结合。在具体的实现上,我们分别从BERT深层模型的最后几层中提取特征通过加法进行拼接,替代原始的字向量输入到BIMPM模型当中。这种做法是和MMD很相似的,只不过MMD中采用各种距离函数,而在这里我们采用的是多种匹配函数。除此之外,我们对BIMPM模型也做了以下修改:
模型的实验结果

为了进行对比,我们第一个结果为BERT单模型的的结果,第二个、第三个则分别为BERT和ABCNN、BERT和BIMPM的结果。在配对深度方面,我们选择了BERT预训练模型的表层一层、表面两层和表面三层,随着层数的增加我们应用了横向合并和纵向合并。
如上表中结果所示,BERT和BIMPM的结合已经比两个单模型的表现要出色。在BIMPM中,我们先去除了Bi-LSTM,其模型的表现降低到了88.55%,如果我们在配对层之后继续去除Bi-LSTM,其模型的表现会降低到87.8%。我们还可以看出,在预训练模型中增加上层模型可以提升几个点的表现,随着层数的增加,可以得到更高的F1值和准确率。
实验二:SLNI子数据集上的问题语义等价
为了确保实验结论的有效性,除去Quora的数据集之外,我们还采用了SLNI数据集当中包含句子等价性的数据集,该数据集包括55万条训练集和10000条测试集。很多学者都用了这些数据来测试他们的模型包效果,对比这些模型,我们的准确率上有将近两个点的提升,达到了目前的State-of-the-art,具体实验结果如下表所示:

问题语义等价的延伸思考
在本文中,我们介绍了一种新的问句语义匹配模型,在后BERT时代,该模型的核心思想是通过抽取语言模型中不同层的表示而达到更好的匹配效果。针对目前层出不穷的深层预训练语言模型,例如Roberta、ERNIE、XLNet等,这种思路无疑是值得尝试和探索的。从简单的层面来说,对于一些不同的基础NLP任务,例如文本分类、序列标注、关系提取、语义分析等,我们完全可以通过提取不同层面的特征来提升效果。从更广的角度而言,MMD在计算机视觉领域的域迁移取得了良好的效果,而在NLP领域目前尚无采用深层提取特征的尝试,而这种尝试从逻辑上来说应该是完全可行的。在目前半监督学习和域迁移正成为NLP研究热点的情况下,这种思维可以作为一种重要的尝试方向。
从一个角度来说,对于问句语义匹配来说,虽然我们提出的新模型达到了很好的效果,但是对于智能对话系统来说,仅仅应用一个等价性模型并不能解决全部问题。举例来说,由于问题库当中的候选问句较多,如果每次用户提出问题都要匹配问题库中的全部问句,显然是不现实的。这种情况下,有至少两种解决方案:一种是通过network distillation的方法或其它网络,降低单次推理所耗费的算力和时间,但是这种方法所带来的效果往往是有限的;更现实的一种方法是先通过简单的算法召回一部分候选问题,但是这种情况下如何平衡召回率和效率却并不简单。
此外,在本文中,我们只考虑了问题语义等价或不等价的情况。但如果问题库不够完整,在没有识别出等价问题的情况下,仅返回安全回答常常会降低用户的体验。在这种情况下,通常的做法是返回相似或相关的问题,这是一个问句语义相似度的计算问题,也是我们需要进一步研究的。