
- 企业服务
- 数据智能

五六年前如日中天的Hadoop生态,催生了大批的创业公司,资本市场也一拥而上,颇有颠覆传统计算存储厂商的态势;时至今日,美国市场巨头合并,股价下挫,中国市场资本热潮消退,头部企业开始推出自研云平台和硬件设施,自建生态。构建闭环商业模式成为新趋势。
2018年10月Cloudera和Hortonworks以52亿美元合并,意味着Hadoop向着统一的标准迈进了一大步。
但合并之后的Cloudera活的并不好,先是首席执行官离职,财报业绩不及预期,然后今年6月股价暴跌超40%,时至今日虽然股价有所回升,市值达到25亿美元,但距离去年10月合并时的52亿美元依然是腰斩。
除此之外,宣布新推出的核心产品CDP的形态还不确定,导致客户不知道该在原版本上升级还是等待整合后的统一版本,严重影响了客户体验。
现任CEO Reilly在第一季度的财报电话会议上也提到,Cloudera现有客户似乎都因为这个问题推迟了续费。
而对于新客户,那就更不知道该选择现有产品还是等待CDP发布。
回到国内,Hadoop生态的基础软件提供商竞争也异常激烈,除了崭露头角的创业公司红象云腾、天云大数据和星环科技,还有盘桓多年的传统数据库厂商人大金仓和南大通用。另外,一众集成商巨头如华为、浪潮和亚信等也开始跑马圈地。
聚焦于国内初创公司,从公司估值、产品健全度、业务线边界、自主研发能力和生态落地情况等方面分析,爱分析认为星环科技是其中的标杆公司。

拓宽业务边界,整合产品能力
成立于2013年的星环科技,以一站式大数据平台TDH为切入点,之后每年均有新产品、组件发布,包括2014年大规模试点部署的实时流计算引擎Slipstream,2015年发布的数据挖掘产品Discover,2016年发布的超融合一体机和StreamSQL技术,2017年发布的人工智能产品Sophon和2018年发布的云产品TDC以及分布式闪存数据库ArgoDB和分布式图数据库StellarDB。
产品不断丰富的星环科技,在业务扩张的背后有清晰的逻辑支撑,一直沿袭着商业和技术两条线的核心目标迈进。
商业上的核心目标,是将业务边界拓宽,通过构建一个包含计算、存储、数据和应用一站式服务的商业私有云平台,把IT所需要的基础设施、中间件和PaaS平台全都一站式解决,必要时候也承接应用的开发。这样能更好地服务客户的扩容需求,同时最大化业务收益。
技术上的核心目标,是融合容器云、大数据和深度学习的能力,通过在存储引擎上面增加深度学习算法,将深度学习引擎和存储引擎融合,可以更好地处理实时数据和非结构化数据,让原本应用范围较窄的深度学习通用化发展。
两年前,爱分析曾对星环科技进行了采访:基础软件市场巨头林立,星环科技如何站稳脚跟?与两年前相比,星环的产品有重大进展,完成了去Hadoop化,成立了单独的人工智能产品线Sophon,全自主研发了分布式闪存数据库ArgoDB和分布式图数据库StellarDB。
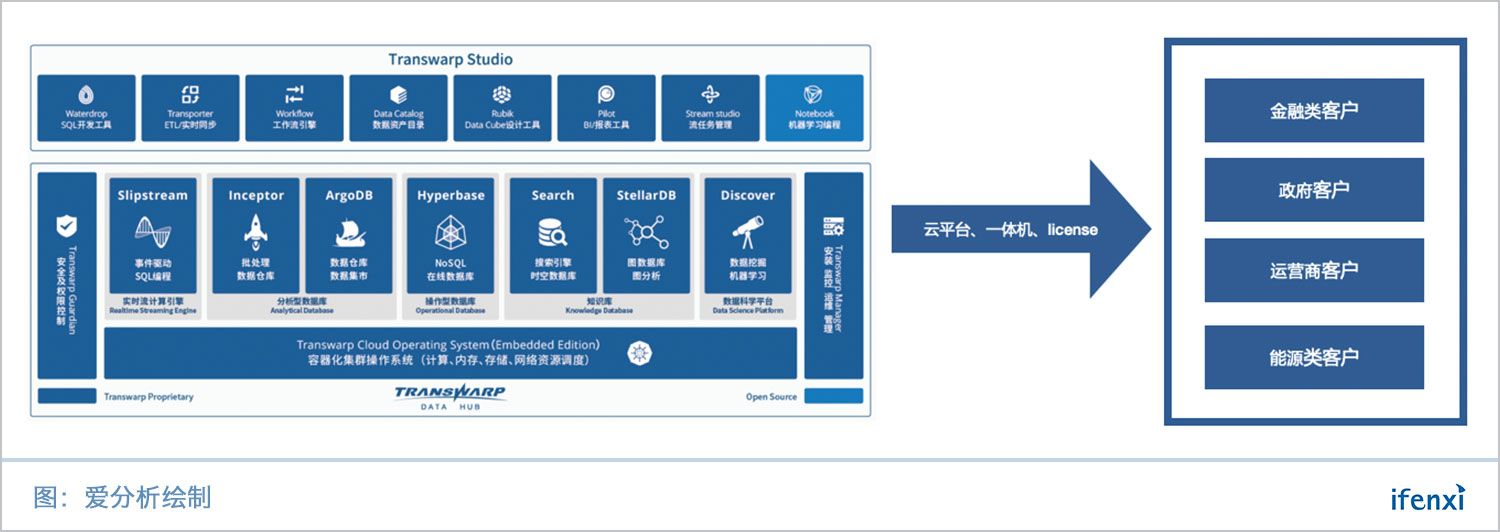
整个产品架构分为三层。
底层TCOS是容器云平台,所有产品实现容器化部署,提高了部署和交付的效率;
中间层是星环科技的七大产品,划分为五个产品集,包括实时流计算引擎,分析型数据库,操作型数据库,知识库和数据科学平台;每个产品集内包含1~2个产品;
上层是各类工具,帮助客户更好地使用七大产品。
伴随着产品更新,星环科技的客户群体也不断扩张,目前已覆盖金融、政府、能源、交通、教育、制造业、运营商、传媒等十多个行业,知名客户包括财政部、国家邮政局、国家商标局、中证监测、中央国债登记结算有限公司、中国期货市场监控中心、中国人民银行、中国进出口银行、国泰君安、招商证券、易方达基金、上海大数据中心、广东省高级人民法院、中国邮政、中国石油、广州供电局等。
发挥各条线优势,实现ABC全面融合
常见的产品扩张策略可以简单分为聚焦业务线的纵向深入和开拓业务范围的横向扩张。经过多年大数据业务积累,发布了单独的人工智能产品线,和容器化的底层部署平台后,星环科技开始横向扩张产品线,推出了新一代智能大数据云平台TDC。
TDC主要提供三个核心模块,分别是DB-PaaS、ApplicationPaaS和Analytic PaaS,以此有效的融合数据、应用和智能。
数据融合方面,TDC已提供几乎所有的数据库品类,包括分析型数据库Inceptor、闪存数据库ArgoDB、实时计算引擎Slipstream、交易数据库KunDB和NoSQL类数据库,NoSQL数据库覆盖图存储、Bigtable和文本搜索等应用,所有的数据库都采用分布式技术来实现,并大规模在生产落地,能提供目前市面上最完备的DB-PaaS能力。
应用构建方面,TDC提供提供齐全的PaaS能力,包括Spring Cloud、go、NodeJS、python、java、PHP在内的标准化的应用开发框架,帮助研发团队更快的开发和运维微服务,企业则可以将通过TDC来建设DevOps流程。
智能分析方面,TDC的分析平台提供了Transwarp Studio工具集,其中包含数据开发IDE、数据任务调度、数据同步与ETL、OLAP Cube建模在内的图形化开发工具,可以大幅提高大数据开发效率。也提供了数据资产管理和可视化分析工具,配合跨租户的数据交换和共享,能够加速数据工作者之间的协同创新;智能建模方面,TDC平台提供了Sophon,可用于端到端的数据建模,其中Sophon NLP、知识图谱、视频分析等模块可以更加直接的给应用提供智能的推动力。
去Hadoop化,自研新框架适应新一代技术环境
星环科技的创始团队来自研发国内首个Hadoop发行版的技术团队。
2013年,孙元浩带领原Hadoop发行版的核心团队,创立了星环科技。
创业初期,他们选择Hadoop作为产品研发的基础框架,除了团队的经验积累外,一方面是技术落地快,另一方面是能借助开源项目已有的品牌和生态解决自身冷启动问题。
但随着星环科技的产品和业务不断发展,Hadoop在技术和商业方面的局限性慢慢凸显出来。
技术方面,Hadoop作为基础框架,其设计需要结合硬件情况,而Hadoop诞生的年代是低速硬盘,低速网络时代,如今的硬件是高速网络、高速的闪存盘,因此在未来几年之中服务器的硬盘就会被全部撤掉,也就是说Hadoop不适应新的硬件了。
当然,选择打补丁的方式,对框架修修补补也可以用,但是在技术快速变化的今天,这样的方式很被动。
商业方面,Hadoop是开源软件,一方面基于Hadoop生态的竞争者众多,除了专注于大数据平台的竞争对手外,不乏华为、阿里等基础云平台厂商,长远来看不利于发展;另一方面国内客户对开源产品的商业模式认可度低,并且无法判断基于开源技术开发的产品有何差异。
而星环科技的创始团队技术基因浓厚,本身就擅长研发,还具有丰富的框架设计和开发经验,慎重考虑后,选择了完全脱离Hadoop框架,重新设计研发自己的大数据处理框架。
自研框架发展,生态建设是关键
作为平台型软件提供商,星环科技脱离Hadoop的决定不仅意味着要面对研发难题,同样重要的问题是生态建设如何进行。
关于此,星环科技创始团队的逻辑很清晰,主要考虑了市场份额,研发能力,实时策略和未来客户迁移几个方面。
首先星环科技在金融、政府等领域的市场份额均超过60%,团队优秀的技术和产品能真正解决客户问题,自身具有良好的口碑。
其次,由于团队的勤勉以及对生态的专注,星环科技的软件更新速度比Hadoop快2年左右,总能赢得客户的青睐。
而关于新生态落地的具体实施,星环科技认为,必须要有标准的接口才能形成生态,因此一方面大力度投资API开发,另一方面在筹备使用标准语言的全新产品,未来客户将基于星环科技自研的计算机语言使用该产品。另外还为合作伙伴提供基础工具,加快生态应用的产出效率。
除此外,转型后的客户迁移问题星环科技也早有准备。对于原先在星环科技平台上使用Hadoop的客户,星环科技自研的新平台有统一的SQL接口,如果客户使用的是Hive,可以直接迁移;而如果使用的是Spark的API则会有一些繁琐,但目前来看,使用Spark的客户很少。

近期,爱分析对星环科技创始人兼CEO孙元浩进行调研访谈,具体探讨了星环科技一年多以来的产品进展,未来方向和具体落地的思考,现将精彩内容分享。
产品线三大变化,打造闭源商业生态
爱分析:从2017年的上半年到2019年,产品和行业本身有没有一些新的拓展方向?
孙元浩:TDH今年5月份发布了6.0版本,其中一个比较大的变化是我们底层全部容器化了。用容器编排系统来做资源调度,可以弹性的创建和销毁大数据平台资源,我们称作微服务架构。
到了6.0版本,我们在产品线上做了很多调整,独立出新的产品线。主要产生了三个大的变化。
第一个变化是我们新推出了数据库产品,分布式闪存数据库ArgoDB。它的底层存储引擎是用C++重新开发的,可以充分发挥闪存的效率,而且跑在硬盘上效率也不错。还推出了全新开发的分布式图数据库StellarDB和交易性数据库KunDB。
以前我们使用开源版本的数据库,但是发现扩展性都不太好。而且要么就只能做统计分析,要么就只能做查询,不能两者兼顾,所以我们重新开发了一套自己的图数据库产品StellarDB。
过去三年多的时间中,我们先将计算引擎改造成自己的,然后不停的改造我们的存储引擎,最后在去年的新产品中发布。加上我们之前开发的五个产品,八个工具,意味着我们分析数据库的系列产品全部由自己打造。
这样一来就兼顾数据仓库、数据集市、数据湖、应用场景,使之成为一站式的,不再需要由多个混合架构来组成了。这是数据库上面一个大的变化,做了一个改造和重构的过程。
第二个大的变化是我们把机器学习相关产品给分离出来,做了一个独立的产品线,形成一个机器学习的建模平台,而这上面又演变出了四个子产品,
现在星环科技人工智能也是一个大平台,对应有四种不同的引擎,包括统计、机器学习、深度学习还有图的分析引擎,在上面就提供了一个交互式的建模工具。
第三个大的变化是17年实现的容器化产品,变成了私有云产品,将应用、数据、模型统一化,可以提供IT所需要的基础设施、中间件、PaaS平台包括应用hosting。
技术上大数据、容器云和深度学习在互相融合,在技术融合的过程中,星环科技就已经抓住了这样的趋势,我们的技术判断还是很准确的,也可以看到包括国外的厂商也在跟随星环科技的技术发展做产品和策略的变化。
业务上的变化就是拓展了一些新行业,金融、政府、能源、交通、制造、教育这些行业都有覆盖到,覆盖将近20个行业。
爱分析:目前星环在全面的去Hadoop,可不可以理解成逐步转向一个真正闭源的商业化产品公司?
孙元浩:我们其实并不是为了去Hadoop而去做,是因为我们发现Hadoop的技术发展已经触顶了。Hadoop这个技术有很大的局限性,它是为上一代硬件设计的,那时候是低速硬盘,低速网络,但现在的硬件是高速网络、高速的闪存盘,服务器在未来两年内会把硬盘淘汰,就是说Hadoop不适应新的硬件了。
而且Hadoop的设计理念是用来做互联网公司的数据仓库营销系统,一次写入多次读取的设计理念,但是很多行业,会进行数据修改,需要保持数据一致性。在Hadoop上进行修补会增加很多人力和时间成本。
星环科技做技术重构的驱动力,还是顺应技术的演进,提供最好的产品服务客户,才是我们做重构的核心原因。恰逢行业和大环境的趋势,其实是星环科技紧抓技术演进的连锁效应。
爱分析:如果完全抛弃到Hadoop的话,会不会对获客造成影响?
孙元浩:首先我们目前在部分细分市场占有的市场份额已经接近百分之七八十了,客户数量多的能达到几百个,这慢慢形成了一种氛围,就是客户已经不关心品牌是星环还是Hadoop;
然后客户真正关心的,其实是产品能否解决客户的问题;我们有自己独树一帜的技术路线,在技术不断演变的过程中,持续推出新的功能,创新速度和cloudera相比领先两年以上,有明显的优势。
因此客户对我们是比较认可的。这反过来又影响着我们星环的品牌,促成了良好的客户氛围;两者相辅相成,互相促进。
当然了,不排除有少量客户,总觉得美国的商品肯定比中国好,美国技术肯定比中国领先,看到我们领先的技术和产品,刚开始会质疑星环科技的技术路线,但随着cloudera多次宣布他要实现星环科技已经实现的功能的时候,客户就慢慢相信了,我们的技术确实是领先的。
爱分析:客户如果第一期用了Hadoop搭建的大数据平台,后面迁移到星环科技的平台上会不会有难度?
孙元浩:我们的接口都是标准SQL接口,是互相兼容的。客户如果使用Hive的话,基本上可以无缝迁移,但使用API,比如Spark的API的话,相对来说会比较复杂,但技术上已经完全不是问题。
爱分析:如果星环科技完全做成一个闭源产品之后,合作伙伴的生态体系搭建会受到很大影响吗?
孙元浩:生态的衡量标准不在乎是开源还是闭源,而是产品接口是否足够灵活强大,能解决客户的问题。最初我们就倡导,大家不应该关注底层API,应该在平台上提供统一的编程语言,掩盖底层的实现细节。
目前我们的大数据平台提供SQL、R和Python三种语言,用户和生态伙伴就不必关心底层使用哪种引擎实现,就可以极大程度的降低开发成本。
这个理念目前已经被大部分大数据厂商接受了,现在大部分产品都提供SQL接口,包括图、搜索引擎和分析型数据库、流处理都提供SQL接口,这是大势所趋。
所以我们认为提供标准接口才是容易形成生态的。
反观今天Hadoop上面的应用厂商,换了一批又一批;应用还是很简单,丰富度也不高,这说明它的生态发展其实没那么好。
星环科技的理念是全系列产品支持各种语言,对用户而言不需要学习新东西,立刻就能开发,极大降低了用户的使用门槛;这样就容易形成稳固的生态,。
另一方面随着我们平台上的应用越来越丰富,效果越来越好,就能吸引其他的供应商往我们这边转。
比如我们做数仓、集市,做风控,做复杂的深度学习应用,包括图分析的应用,很快就能形成示范效应,大家会发现开源下无法实现的,星环科技的产品可以实现。这种示范作用其实更利于形成生态汇集。
专注容器云和数据服务,积极拓展业务边界
爱分析:在私有云平台实施的时候,星环会把容器平台部分的工作一起做了吗?
孙元浩:容器编排系统以及再往上一层,包括调度框架、存储引擎、网络机制都是我们做的。
14年我们就开始做容器化,当年CCF的会议上我们就公开提出,我们希望借助容器化进行调度,当时还有很多技术路线,大家都还在犹豫,所以星环科技做容器化部署,是比绝大多数公司都早的。
爱分析:除了单机容器不做,和其他的云公司会比较类似吗?
孙元浩:国内很多公司可能用Mesos、Docker,慢慢再过渡到Kubernetes,我们是国内比较早期在Kubernetes做改造的公司,把CPU调度、网络和存储都做了改造。
星环科技是唯一的一家能够在Kubernetes上面提供大数据的厂商,因为要对Kubernetes和Hadoop进行大量改造,需要有技术眼光和研发能力,国外也有些巨头公司专门成立小组进行,但至今都没有实现。
爱分析:星环未来几年的定位是什么样的?
孙元浩: 星环科技现在依然专注在企业级容器云计算、大数据、人工智能核心平台的产品研发,希望成为全球领先的基础软件供应商,向Oracle和SAP学习。
爱分析:对于传统行业,您觉得TP的业务如何切入?
孙元浩:星环科技已经推出了我们的TP产品KunDB。
我认为目前可行的切入点有两个,第一个是信息安全、自主可控的方向;第二个是云上提供弹性TP服务,随着私有云的部署和公有云的普及,会是一个刚需。
数据量不断增大,客户需求不断变化
爱分析:从业务、技术或者客户群体的角度来考虑,实时性需求背后的原因是什么?
孙元浩:有一些场景是需要实时性支持的,比如实时交易监测,是市场行情的交易情况,往往需要在秒级立刻作出分析并且同步到后台,后台立刻计算风险模型,选择是否作出预警。
这个需求不光是流处理,还要做复杂分析,模型很复杂。我们在流的产品上提供微积分功能,就是可以应对这样的需求。
爱分析:这个核心是技术上需要大规模的改进是吧?
孙元浩:它的核心就是要对计算引擎做改造的,这里分成两部分。
一部分中间要插个流处理引擎,这个流处理引擎上面肯定要做到几毫秒延时的话,它需要事件驱动的。但是它这个编程模型又非常复杂,比如说求解微分方程,做机器学习,甚至重组过程,控制流,要有SQL统计,这块要做的非常快。
过去认为这点做不到,因为做实时处理的话,要么是事件驱动的,规则很简单,要么就是把事件流按时间切片,如果每个时间切片上做的比较快的话,等效于是实时流处理。
当时大家认为这两者是不可调和的矛盾,星环科技在2016年实现这点的时候,引起了行业的震动,实际上它是要对引擎做彻底的重构,后续也有国外厂家在2018年推出了同类产品。
爱分析:除了底层平台的需求外,客户这一两年有没有产生一些新的需求?
孙元浩:目前来说,首先增量需求主要来自于数据量和计算资源的需求,数据量增大之后,基础平台需要不断扩展,客户在其上的应用较多的有五六十种甚至上百种应用了。
比如我们有一个大客户,他在平台上跑批处理流程有超过一万个,结果计算量大增,这是主要需求。新的需求主要是数据分析,图分析等。
实时处理也是一个主要的驱动力,主要来自于两方面,一个是金融机构需要做实时决策,另一个是由于5G的推动,物联网的需求多了起来,传感器的数据一直是要求实时性。
总的来说,数据量和计算需求的增长,实时性需求增加,复杂分析的需求增加,都是造成底层需求增大的因素。
国内市场竞争激烈,国外厂商发展遇瓶颈
爱分析:目前国内底层厂商的市场格局如何,还像2017年一样激烈吗?
孙元浩:今年还是相对比较激烈,我认为还会持续1-2年的时间。
从美国市场的情况看,由于通用型产品的高产品质量和高研发门槛的要求,底层厂商的市场在发生收缩。
一方面,是Cloudera和Hortonworks的合并,将给价格战带来一个终结;另一方面,是大玩家的退出,IBM转去使用Cloudera或者Hortonworks产品。
因此,美国市场今年基本完成了市场的整合,而据经验判断,国内环境通常会延迟一两年于美国市场,目前,技术路线上的厂家已经为数不多了,正在向整合的方向演化。
爱分析:关于Cloudera和Hortonworks的合并,有种观点认为行业内两家企业的合并一定程度上代表着行业遭遇了明显的瓶颈和天花板,您对此有什么看法?
孙元浩:这个问题要从两个角度来看。一方面,从客户的角度来看,合并未必是一件好事,因为垄断程度的上升的必然带来提价,因此,客户会付出更高的采购成本。
另一方面,从供应商的角度来看,也许是一件好事,它代表着市场逐渐回归进入良性的竞争。因为两家合并以后必然会一定程度上结束前面的恶性竞争,进入一个市场收割的阶段。
就像早年的数据库市场一样,由最初几十家经过一段时间的市场竞争最后只剩下几家,所以,从这个角度上讲,我认为这种合并可能是市场走向良性循环的一个起点。
爱分析:理论上讲,类似Cloudera和Hortonworks这类底层软件厂商的产品化率和毛利率应该显著高于上层应用厂商,然而实际情况却相反,它们的规模化效应并不明显,营收增速也慢于上层应用厂商,您如何看待这个现象?
孙元浩:首先,Cloudera和Hortonworks的这个模式是非常好的模式,订阅的、高度产品化的模式带来的是可复制化和客观的维保收入。
这一点我们从Elasticsearch和MongoDB在资本市场的高估值就能看出,他们同样是大数据中的一环,并且拥有很高的产品化程度和续购率。
我个人认为,Cloudera和Hortonworks的发展瓶颈大致可以归结为两点。
一方面,它们的产品化程度不高,重咨询的商业模式,导致实施成本过高,然而如果产品化程度提升的话,服务费收入又会下降,这是这类商业模式的一个两难境地。另外,由于创新能力的缺乏,它们的上层应用不够丰富,也是产品层面的一个制约因素。
总之,虽然营收状况良好,但较低的产品化程度制约了它们的成本下降空间,造成了他们的亏损。
另一方面,是市场的恶性竞争,Cloudera和Hortonworks将技术开源以后,很多大型公有云厂商或类似IBM、HP之类大厂都在基于免费版本开发产品在销售,一定程度上侵蚀了他们的利润。
因此,Cloudera和Hortonworks合并以后,新的订约协议和软件发行模式已经于9月开始执行,它们的收入和利润随之自然会上升。
爱分析:最近,我们观察到一些头部客户的客单价在显著提升,比如国家邮政,您认为这种客单价的提升主要原因是什么呢?
孙元浩:主要原因是技术的成熟和用户接受度的提升,简而言之,客户通过一段时间的使用已经逐渐认识到它的价值,因此加大了投入。
任何技术产品的落地都会经历一个小规模试用到大规模推广的过程,那我们为例,我们早期的客户可以只买6个节点,规模很小,但当他们经过尝试性使用,认识到应用场景广度及使用价值之后,逐渐就把它作为全企业的一个统一平台,通常都在千万级以上。