
- 人工智能
- NLP

三位颇有渊源的技术男,在2018年初聚首,决意在NLP领域搞点大事。
这个事即是成立百炼智能——中国第1亿家市场主体,期冀用NLP对互联网信息进行重新组织,将庞大、繁杂的信息转化为简单可用、可信赖的知识,帮助企业显著提升获客的效率和效果、最终提高每个人知识获取的效率。
百炼的创始团队中,冯是聪此前是秒针的技术VP、明略数据的联合创始人兼CTO,与姚从磊是北大天网实验室的师兄弟;而姚从磊此前任职豌豆荚和全球最大AI输入法公司Kika的CTO,另一位联合创始人佘伟毕业于隔壁清华,与冯是聪共事于秒针和明略,曾担任明略研究院院长。
创始团队的光辉履历,加上两个老东家的资本支持,NLP赛道的被看好和热门,天时、地利、人和都具备了。
技术和需求驱动
姚从磊在博士时期,北大天网实验室曾有一个“FAME”项目,基于公开信息,围绕名人、名人的信息和名人之间的关系构建知识图谱。这一出于兴趣的项目以失败告终,失败的理由是彼时中国只有4亿网页,信息不够丰富,而现在有2600亿网页,公网信息的丰富程度不再是问题。
除了数据丰富程度的提高,在过去这些年由于深度学习的发展,NLP技术也取得了长足的进步。对海量文本进行分词、命名实体抽取、实体属性提取以及实体关系的定义和识别,百炼智能认为在这个时点,技术已经达到可用性阶段。
除了数据丰富、技术成熟,创业要实现商业价值就必须考虑需求,对需求的判断来源于创始团队的经验。明略数据证明了利用企业内部数据构建知识图谱的有效性,同时明略在服务客户的过程中,也对利用外部数据信息服务客户有强烈需求,而在对公网数据进行整理和抽取方面并没有公司做得很好,市场存在空白。
正是基于对数据、技术和需求三方面的判断,百炼团队认为创业的各方条件都已经具备。
打造知识引擎,聚焦五大行业
百炼智能的数据主要是通过公网爬虫获取,同时在服务客户时,客户可以将自己数据加进去作为补充完善。百炼智能将公网数据进行清洗、抽取、推理,从而生成知识图谱。
知识图谱的关键构成要素是实体、属性和关系。百炼智能织就的知识图谱,实体主要是人和机构,人员以各个公司的决策层为核心,机构则包括企业、NGO、科研院所、协会等各类机构。围绕这些实体,标注这些命名实体的属性,并且将实体之间的关系界定、关联好。
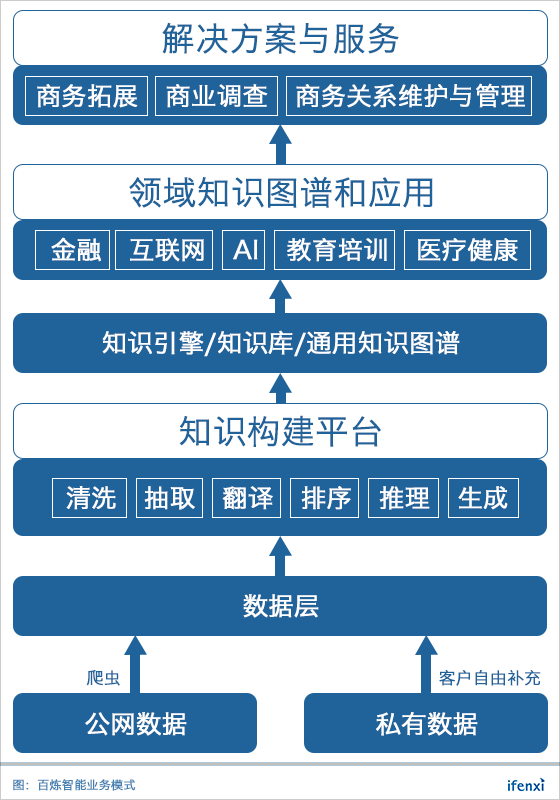
由于全网数据量浩繁庞杂,作为创业公司的百炼智能,不可能一蹴而就织出一张覆盖整个互联网的“天罗地网”,因此,百炼智能选择了从一个一个行业的“小网”开始织起。
现阶段,百炼智能聚焦打造5个行业的知识图谱:AI、互联网、金融、教育培训和医疗健康。选择行业的标准,主要是考虑该行业机构和人员的信息在互联网上的可获得性,以及该行业对知识图谱的需求强度。
除了聚焦于5个行业,百炼智能现有服务的近20家企业客户,以C、D轮创业公司居多,这些公司对新技术的尝试意愿和接受度高、决策迅速且关注效果。百炼智能希望通过服务每个行业的早期几位客户,打磨产品,构造易用性高的行业图谱,从而复制到整个行业。
服务企业“攻”与“守”
构建好知识图谱,下一步是选择落地场景。要产生商业价值,或者帮客户赚钱,或者帮客户省钱。NLP帮客户省钱的场景有智能客服,百炼智能选择的是帮客户赚钱的方向。
通过围绕人和机构打造的知识图谱,百炼智能可以帮助企业的销售团队发现销售机会,并且通过企业的“全息档案”知道内部组织架构和关键决策人,也能利用百炼智能的“百炼人脉”(人际关系的图谱)找到触达目标人物的路径,从而提升销售效率。
除了帮助企业商务拓展,对于已有商务关系的维护和拓展,百炼智能可以进行个性化服务和智能推送。对于销售而言,可能需要重点维护的关系在数百名,他们希望在重点关注的人物和机构有最新消息时都第一时间知道,而如果通过自己在互联网上跟踪和搜索,无疑是不现实的,百炼智能可以为其提供及时推送,节约时间。
帮助销售拓客,这是服务企业的“攻”,而“守”的一侧就是帮助企业跟踪竞品和行业相关机构的动态,从而了解行业发生的变化与新情况,及时做出应对。
现阶段,百炼智能的业务重点是服务企业“攻”“守”两端。与此同时,百炼智能正与基因测序公司合作,在肿瘤患者使用临床实验药物的环节,通过NLP技术来提高知识管理的效率。
肿瘤患者会做基因检测,基因检测后生成的用药建议报告是基于基因变异情况、癌种、使用的药物和药物的疗效之间关系的知识图谱生成的;这一知识图谱目前是由人工阅读海量医疗文献,由人工来维护的,速度慢、效率低。百炼智能希望通过利用AI,自动阅读和抽取海量语料文献,从而构建起从基因点位、变异情况、癌种类别、用药品类、适应症状、药物疗效的整个图谱,提高基因测序公司的业务效率,降低患者负担成本。

近期,爱分析专访百炼智能联合创始人兼CTO姚从磊博士,节选部分内容如下。
基于公网数据构建知识图谱
爱分析:在2018年3月选择创业,是看到哪些机会?
姚从磊:我们三个人挺有渊源的,他们俩是我在惠普实验室的同事,我跟是聪还是校友,后来他们在秒针和明略,我在豌豆荚和Kika负责技术产品。
现在做的事情跟当年读博士做的事情很像,当时做过一个“FAME”项目,围绕名人构建一个基于公开数据的知识图谱。后来项目做的不太成功,主要是当时中国互联网只有4亿网页,数据不够,今年大概是有2600亿网页,这个数据量的变化是很大的。现在很多公司的工商信息、产品业务信息、董监高和总监级别以上人物的信息,在互联网上都很容易找到。
第二个是NLP技术的成熟,从分词、消歧、实体关系抽取到生成知识图谱,再到生成自然语言的文本,这个闭环是能走通的。
光有数据和技术还不够,更重要的是需求。明略在服务客户的时候,也会觉得外部信息的补充很有必要,但这一块并没有做得很好的公司。同时,我们几位在之前做公司的过程中,也有一些感受,比如销售,在商务拓展的时候,需要花费很多时间精力去做准备,去搜集目标客户的信息。
基于这些点的判断,我们觉得时机合适了。
爱分析:现在整个NLP的识别准确率能到什么水平?
姚从磊:这个分很多个层次,第一个层次是分词、词性标注,现在很轻易能做到95%以上,实用性没有问题。
第二是实体的识别和实体关系的分类,如果是在一个封闭数据集上做,我觉得能做80%多的准确度和召回已经很不错。但是我们是在利用整个互联网的数据做事情,会利用互联网上信息的冗余来自动纠错,所以我们现在可以做到95%以上,就是意味着这个最后做出来不会出太大错。
第三是自然语言文本生成,这个事情很难,包括我们有的朋友在Facebook,在Google,他们做起来也挺难的。现在还都是在一个确定的垂直领域可以做得好一点。
爱分析:基于公网数据,是希望打造一个全网的知识图谱吗?
姚从磊:我们的目标是把互联网信息重组一遍。坦白讲,现在的搜索引擎在帮助用户获取知识上非常不方便,很耗时间,也很难判断信息准确性。
所以我们最后的目标是期望能够把它重组一遍,但这个事情太大了,会分领域来做。因为分领域的时候,我们做一家公司才能活下去,有商业价值就能活下去。我们现在会先从B端客户开始切入,B端客户需要什么,我们就把那个领域做深,相当于很大一张图,我们一步一步的把这个图上每一块慢慢的做起来。
爱分析:依赖公网数据去做知识图谱的时候,如何保证准确性?
姚从磊:有两个方面,第一方面是互联网信息本身有个特点就是冗余性,冗余性就是正确信息会出现次数更多,同时不同的网站有不同的可信度,所以我们综合这方面维度,去对信息的可信度做判断。
同时,我们这个服务提供给一个客户的话,客户内部大都有自己的业务系统,这些系统会给我们做一些反馈,这些客户对所在行业的信息反馈会作为我们另外一个维度,来判断这个信息的可信度。
爱分析:这个图谱是会先训练好一个,客户有需求去调用,还是说根据客户的需求去训练一个图?
姚从磊:现在这个阶段,我们是这样,一个客户合同签完了,意味着我们有资金可以直接做这个事儿,就会开始研究客户的需求,把事情先做好,同时我们会扩展到整个领域。
举个例子,比如服务一个快消行业的客户时,我们会逐步的把快消行业的这些机构全覆盖一遍,同一行业各家公司的需求重合度还是比较高的。
实际做起来,还是需要很多个来回,很多时候客户对我们能力的认知不是很准确,我们自己对技术刚开始能做出什么水平也不是很准确,但是往返几个来回后,我们就能知道什么信息是非常充分的,什么信息会很准,逐步会做得符合客户需求。
爱分析:通过爬虫去获取公网信息,哪些是可以被爬取的?
姚从磊:其实在互联网这个行当里,最重要的是大家之间相互尊重,我们会先去分析每个网站的robots协议,在允许第三方爬取的前提下进行爬取,同时充分考虑到不对网站造成流量压力;如果不允许的话,我会想办法去跟它去谈合作。
一般需要谈合作的就是一些最头部的公司网站,其实很多网站是愿意自己的信息被别人索引而获得更多流量,除非是说它的信息是直接用来盈利的,对于这种我们就不会爬它的数据,但是我们会尝试进行合作,或者去爬他它公开的源头数据并进行深度加工,还是有很多方式的。
爱分析:实体主要是机构跟人,实体之间的关系,是根据客户需求去定义?
姚从磊:其实很多时候客户只是说大概,我们内部会有一个相对比较丰富、并且在不断更新的关系体系,以及实体的属性的一个体系。
我们其实会跟客户去聊,问客户觉得什么比较重要,最后能总结出一些重要的关系。比如人和人的关系,一类是同学,一类是同事,还有共同作者,一起发文章,一起共享专利,以及一起出席过某个商务活动,这里面可以分得很细,比如同学关系可以是同年级、同系或同实验室等等,会有很多维度,我们是有这样一个体系。
一开始,比如说人和人,机构和机构的关系,我们能定一些比较通用的,然后我们会根据不同客户的一些需求逐步往上加。这个体系会给到客户,看客户觉得这里面哪些是是需要的。
但这里面唯一不一样的是标签,对有的客户来讲,它有一套固定的标签体系,因此我们是没有一个非常固定的标签体系,我们是通过算法生成。
行业知识必不可少,SaaS方式服务客户
爱分析:知识引擎的打造,需要经历哪些过程?
姚从磊:现在主要是这么几块,第一个是爬虫,第二是实体的提取、关系的分析,第三还会涉及到一些翻译,我们现在也开始支持一些英文信息的处理,第四类是推理,因为很多关系是隐性的,所以会去做推理。第五个,也是最重要的是知识图谱的存储和检索。其实是一个层次结构去处理。
爱分析:推理这个环节,机器是如何实现的?
姚从磊:我觉得是有两个方面,第一个是人为确定统一的规则体系。举个例子,比如我能自动从网上找到某人背景的公开描述信息,这个人是2012-2014年在某公司,那个人是2013-2016年在这家公司,那可以推断他们俩是前同事,如果知道他们是同一个部门,那关系就更密切,这是可以推理出来的。
第二个是我们现在没做,如果发现两个机构或者两个人频繁地一起出现,说明他们有关系,我们尝试给这关系去打标签,但这事我们还没做,因为这个事情从商业角度或实用角度来讲,有些不可控,这个关系比较弱。
关系需要有明确的定义和意义,最好是一个分类体系会比较好,如果没这个分类体系,去推理计算会有问题,就只能打标签,而标签本身的空间其实是很大很发散的,所以我们现在都是基于统一分类体系来做,基于标签的其实还没有去做,前面那一步已经量很大。
爱分析:推理,关系的定义,都需要人为定一些规则,需要懂具体行业的行业知识,这个如何解决?
姚从磊:我们现在都是依靠请外部顾问,这一轮融资完成后,会请一些行业专家加入,结合行业知识把产品打磨得更好,光靠智能算法是不够的,理解没有深度。
但最好的方式还是跟客户一起,把客户需求满足了,就是最好的。
爱分析:在训练引擎的过程中,数据标注如何做?
姚从磊:现在我们基本上没有什么太显性的数据标注,现在互联网好的地方是说它有很多网站提供了一些非常结构化的信息,而这些信息其实我们是拿来可以去做训练数据的,比如名人的背景信息,在百度百科上就很结构化。
另一方面,我们选择的行业和客户,都是在互联网上信息量非常丰富的领域,这也是一大利好。但未来,当进入到一些传统行业,比如印刷行业,可能是需要与客户一起去标注。
爱分析:服务的五个行业里,有多大的差异?
姚从磊:其实差别蛮大,比如说AI或者互联网行业,所有的机构不论大小,整个的结构相对扁平,但是金融类其实就更为复杂,层级更多,所以做组织架构图就会很不一样。
举个例子,比如一个国有银行,很多分行,很多支行,这些怎么处理,这个其实挑战会很大。坦白讲,这个活不好干,我们一边做一边学,才知道金融类的保险,银行,券商其实都是不一样的,有各自很多特点。
爱分析:知识引擎如何交付给客户?服务形式是什么?
姚从磊:我们现在有两种,一种是SaaS,这是我们推崇的,可复制性比较高;另一种是对一些特殊的大客户,我们会做一些定制,但定制的程度我们会比较保守,不希望有太深入定制。
爱分析:收费方式是怎样的?
姚从磊:两种方式,一种是按API调取量收费,另一种是会有一个起始费用,包含一定的使用期限和使用量,后续再按调取次数收,其实我们的方式是比较灵活的。
爱分析:客户采购您公司的服务,通常是走哪方面的预算?
姚从磊:有两种,一种是需求变得很强,会有专门的预算,这类企业通常是在快速拓展期;另一类是走市场营销的预算。