
- 企业服务
- Hadoop
- 大数据
- AI基础设施
- 图数据库
传统Hadoop领域,已经是群雄并起,竞争激烈。如果不能搭建Hadoop平台,普通大数据公司就无立锥之地了。但与只用Hadoop进行事后的数据分析处理不同,天云大数据利用OLTP引擎实现了银行的高并发事物处理。除此之外,一些新的名词,复杂网络、AI基础设施统统都被用在了Hadoop里面。那么,这家企业是如何打造与众不同的呢?
时至2017年,对于涉足大数据业务的企业,搭建一套方便、灵活的Hadoop平台已经不是一件难事。Cloudera、Apache等厂商,帮助企业大幅降低了大数据业务的进入门槛。
不过,大数据平台应用最多的是OLAP(联机分析处理)业务,能够对TB、PB级别的多维数据进行关联分析和数据挖掘应用,但是对于OLTP(联机事务处理)业务来讲,一般的Hadoop平台就显得力不从心了。
2017年7月在北京举办的Strata Data Conference会议上,天云大数据研发总监乔旺龙做了有关《Hadoop上的OLTP》的报告,其中提及天云大数据的Hubble Volmue Transaction Distributed-Engine哈勃大规模事务分布式引擎能在千亿条的数据环境下实现毫秒级别的Ad-hoc业务查询,其处理速度是采用内存计算的Impala和Spark的数百倍。
依靠技术创新,天云大数据成长为一家立足于金融行业的大数据和AI基础设施平台提供商。
天云大数据创始人雷涛拥有超过20年的跨国公司技术管理经验, 2005年入席SNIA存储工业协会中国区技术委员会联合主席,CCF中国计算机学会大数据专委会委员。
业务产品化率高 从大数据平台向AI基础平台转化
2013年,天云大数据发布了BDP大数据平台,与传统的Hadoop发行版不同,BDP是一个中间件平台。中间件的方式拒绝了与特定的发行版进行绑定,Hadoop各个组件之间通过restful接口互相传递消息。
这样带来的好处就是,BDP可以根据业务需要进行适应性升级,只需更改少量代码即可实现,从而轻松解决版本不兼容的问题。
BDP只是一种基础平台,带天云真正实现飞跃的是Hubble Volmue Transaction Distributed-Engine哈勃大规模事务分布式引擎(OLTP查询引擎)、Hilbert Complex Network Distributed-Engine希伯复杂网络分布式引擎(图计算复杂网络引擎)和Maxim AI(人工智能基础平台)三款产品。
作为密切关注国际前沿的技术先驱企业,天云大数据在切入业界前沿和热点上,通常快人一步。如今,OLTP on Hadoop、图计算、AI基础平台等概念已经火热,而天云大数据在内部早已经形成产品,并在商业银行的业务系统上进行了运行和试用。
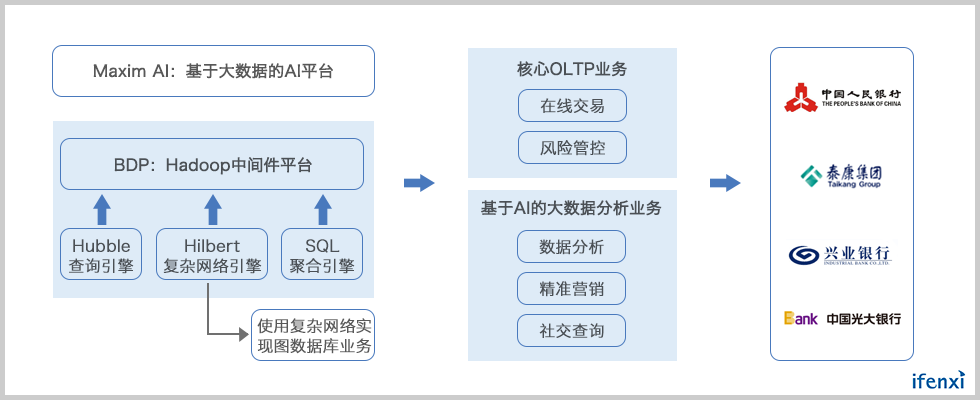
这三款产品带给天云最大的改变是差异化的竞争路径。
银行等企业生产系统的核心通常是构建在IOE平台上的OLTP业务,这部分业务恰恰是现有的大数据平台不能解决的。而哈勃大规模事务分布式引擎正满足了银行基础设施去IOE和系统减负的需求,可以将80%的OLTP业务转移到分布式平台上。
与OLTP相对应的OLAP本是Hadoop的长项,但是只有Hadoop和数据是做不了分析的,对于分析领域最关键的模型和算法,老牌巨头SAS才是该领域当之无愧的霸主。不过,对于长期在关系型数据库领域浸润,2014年才进入Hadoop领域的SAS来讲,磨合还是需要时间的。这给天云研发基于Hadoop 的AI基础平台留下了时间。
复杂网络引擎和AI基础平台这两个新品类的产品,明显不是来自于工程实践的创新,而是理论创新的实践。所以,天云大数据技术优势的积累离不开其博士后工作站的研发能力及其多年来公司团队对Hadoop平台的理解和工程化能力。
立足金融行业,客户支付能力强,但市场扩张慢
作为云基地的孵化项目,天云大数据初始切入的业务以运营商类客户为主,如中国联通的数据魔方项目、中国移动的南方基地项目等。随着公司定位的调整,天云大数据从运营商类业务转到专做金融业务为主,先后承接了中国人民银行、九鼎、信诚、泰康人寿、光大银行、兴业银行等银行、保险、交易所相关的业务。
通过业务领域调整,天云的角色也从传统Hadoop平台集成商向基础软件应用商转变。从竞争对手上看,前一阶段还是Hadoop平台搭建类厂商,而后期竞标对手多为硅谷的Neo4j和TigerGraph等图数据库高新技术企业。
由此,天云大数据业务中心也从搭建平台,转向图数据库、分布式OLTP业务及AI智能平台。
得益于金融行业客户较强的支付能力,天云大数据目前的客单价一般都能超过100万元,与国内传统hadoop厂商相比,相对可观。但目前看,由于客单价较高,项目较少,其规模扩张速度较慢,这将影响其长期发展。
竞争转移,新兴市场潜力大,营收可预期
天云的产品并不属于传统的数据仓库市场,而是进入了OLTP、图数据和AI三个细分小市场。所以,它避免了与目前竞争最为激烈的传统Hadoop基础软件和数据仓库厂商的直接碰撞。只不过还需等待新兴市场的培育,以便释放积累的市场能量。
从市场格局看,图数据和AI平台是目前天云最主要的目标市场。图数据库市场当前主要参与者Neo4j和TigherGraph,虽然营收规模之和才千万级美金级别,但从Linkedin、支付宝和国家电网等客群对图数据的使用需求之强烈判断,未来市场潜力巨大。
在AI平台领域,目前主要是百度天智、阿里数加等公有云AI平台,在私有化部署的AI平台里,其主要竞争对手为在高级预测和分析领域SAS和IBM Spss等企业产品。SAS凭借32亿美金的年收入和超过100亿美金的估值,成为40年金融业屹立不倒的常青树。随着大数据的广泛应用,基于人工智能的高级预测和分析,预计还会有指数级的增长。
图数据库和AI平台业务的爆发指日可待,2017年天云大数据营收增速预计超过200%,这缓解了前三年市场扩展缓慢的焦虑。在客户渠道畅通的情况下,预计天云大数据2018年还将保持80%-100%增速。
评价模型
爱分析从应用场景、获客、客群、产品、技术五个维度对天云大数据作出评价。
技术层面,天云大数据拥有成熟的Hadoop中间件平台,具有搭建大数据业务平台能力;在复杂网络和AI数据分析领域积累多,在国内具有先发优势。
产品层面,其Hadoop平台、复杂网络引擎和AI平台等业务的产品化程度高,能够实现快速复制。
客群层面,天云大数据的客群主要在金融领域,市场规模大,客户支付能力强。
获客能力层面,从天云大数据近3年发展速度看,其获客能力一般。
生态层面,天云大数据作为初创公司,还未搭建完整的生态链和客户关系,在生态环境里还处于劣势地位。
近日,爱分析对天云大数据CEO雷涛进行了访谈,现摘取部分内容如下。
爱分析:天云大数据与一般的Hadoop平台公司有明显差别,您对Hadoop是怎样理解的?
雷涛:2012年以前,我们主要是在使用Hadoop技术阶段,在别人不会用时,我们率先使用了。当时,我们做的多是企业级大型运营商项目,必须进行很多改造和优化。我们在Hbase上做了大量的数据库回滚和数据库审计操作,并且做了有一些新特性,像master sever 切换等管理功能。
但到了2012年,CDH 3.0版本发布对我们是重大的打击,那个版本覆盖了我们很多功能。面对继续在旧版本上开发,还是发行新版本的产品两个选择,我们就出现了一段时间混乱。
后来,我们选择在2013年彻底重构产品。我们把平台中自己的套件拆分出来,做成了一个中间件,所以我们不是发行版。我们的中间件下层对CDH、Apache和Hortworks进行了混配,通过600多个restful接口进行消息互通,拒绝了发行版的锁定和绑定。
这带来了几个便利,第一中间件与版本无关,可以持续升级。对于团队来讲,不用每一次大版本升级时做代码review,这就拆分了功能研发团队和Hadoop研发团队。第二,这还带了很多开放性,表现为对集群的多样性支持。例如在九鼎,其原有搭建了Apache集群,再装套其他集群就需要推到重来,这是难以实现的。由于我们采用开放接口,我在统一数据和资源管理下,允许多集群管理。第三,开放之后的产品可以融合更多项目,我们可以在差异性的环境中做功能套件的融合。
爱分析:天云大数据业务范围涉及图数据、AI、和Hadoop on OLTP几块领域,那么现阶段的主要竞争对手是谁?
雷涛:我们PK掉的是Neo4j、graphsql这些硅谷的新锐公司。
爱分析:天云大数据从运营商转到金融领域的契机是什么?
雷涛:天云大数据注册在2013年,实际上是2015年才正式成立的,但是我们创始团队在2010年云基地的时候,就在一起了。我们早期做了很多运营商业务,如联通的数据魔方、移动总部、南方基地等。但独立以后,我们做了差异化的区分,为了避免同业竞争,我们聚焦在金融领域。
由于我们对业务做的比较深入,第一个单就进入一家商业银行的核心系统,一个OLTP线交易系统。这个业务客户市场比较少,但是门槛很高,客户质量都很好。这些客户包括中国人民银行、兴业银行、泰康人寿、信诚人寿、九鼎、京东等。
爱分析:天云大数据是怎样进入AI领域的?
雷涛:我们在2011年南方基地的项目就开始使用机器学习技术了。那时我们招募了大量的数据科学人才,并建立了自己的博士后工作站。当时我们沉淀了大量的工具包,像NLP、神经网络、时间序列等等。
我们在银行的项目发现一个问题,银行要求Hadoop与SaS对接,但是对接了SAS后,后者性能又不能满足要求,我们只好在Hadoop上重新写分布式程序。
2016年,我们在之前工作的基础上直接打包了AI平台,也拿到第一个AI基础设施800万的订单。我们正好踩到了AI的PaaS化这个时点,基本跟TensorFlow同步推出。我们融合了Torch、Caffee、TensorFlow和我们自己的大量算法,可以让客户在Online集群之上直接跑各种算法,在算法和数据之间我们做了非常好的融合,让算法能够充分使用。
我们现在有两种方式,一种是Free coding,直接调用模型,调节参数;另一种在Notebook环境,使用Python 编写新算法。这大规模提高了模型的生成速度和效率,并且大大降低了人才依赖。
我们发现,我们平台交付给客户后,数据对模型的选择发挥了巨大价值,一个分类器将随机森林、逻辑回归和深度学习全跑一遍,然后选择AUC曲线最好的模型。这意味着以前半年才能完成的事情,现在只需要5分钟就能完成。使用者的试错成本大大降低了,凭借强大的计算能力,银行就可以实现模型的规模化生产。
爱分析:对于OLTP业务来讲,一般的银行交易量有限,中小型城商行Oracle就可以实现,少量大型银行MPP也可以实现,大规模的高并发需求除了BAT等少量的互联网企业并看不到很大的需求,为什么还需要在Hadoop上做OLTP呢?
雷涛:我们现在看到的现象是,出现了很多银行接入互联网的项目,现在银行的服务界面已经不仅仅是柜员了,银行手机端内容越来越丰富,在全业务领域承载的越来越多,渗透率越来越高。手机端的银行交易带来城商行大量大规模高并发需求,这个需求既有大量对Oracle和MPP的需求,同时也带来对Hadoop on OLTP的需求。
爱分析:天云大数据目前采用什么样的方式开拓市场?
雷涛:现在一直在替代一些原有银行里的业务形态,最近几个项目都是在翻竞争对手的客户。我们看到一个趋势,竞争对手在依靠市场增量拿新单,不断迈入新市场,而我们从1到3到20这种倍率的增长,全是在一两个核心客户完成的。我们的新客户都是竞争对手的客户切入我们的领域的,所以我们在垂直增长。
我们相信在早期市场环境下,产品的市场价值必须做得足够厚才行,而不是只做开源部署的调度管理。否则,你在开拓新市场的时候,你的市场也会被其他企业吃掉。在目前分布式的市场环境里,企业必须沉的足够深,有自己的积淀,找到适合自己的位置,才能体现市场价值。
爱分析:产品的交付形式是什么的,是卖平台呢,还是按照工具包进行销售?
雷涛:我们在项目边界上是这样的,首先我们之前没有平台,只能提供工程服务。例如我们跟城商行进行交易时,他们一般会按照工程服务进行选择,不会考虑到平台的问题。
对于大型银行来讲,他们会招两种平台,一个是先招个平台标,建立基础设施。招完平台标以后,在平台之上会按照数据产品进行招标,每个数据产品就是我们做好的内容,这些数据产品可以交给业务部门直接使用。
以前,人工智能和机器学习在银行里面就是SaaS+服务,生产出来后放到决策引擎中使用,是静态的;现在是平台加数据产品,生产出来的东西直接在平台运行,它不再是静态的,而是动态的一个过程。